Mapas de puntos con Python
Conoce y aprende a hacer este tipo de mapas que es muy útil para visualizar resultados electorales geográficamente.
En esta entrada les cuento sobre este mapa de puntos que hice y tuvo bastante eco en redes sociales.
Y a petición de @tomasdamerau, incluyamos a los que no votaron (boletas sobrantes) pic.twitter.com/iB339vc7OE
— Juan Javier Santos Ochoa (@jjsantoso) June 8, 2021
Se trata de un mapa de puntos, también conocidos como mapa de distribución de puntos o mapa de densidad de puntos. En este tipo de mapa los polígonos de cada región se rellenan de puntos que representan una cantidad fija. Cada punto puede representar una sola observación o varias, lo importante es que ese valor se mantenga fijo y no varíe, como pudiera ser en un mapa de símbolos proporcionales. Cuando los puntos tienen el mismo valor es mucho más fácil hacer comparaciones. Normalmente la ubicación de cada punto dentro de la región que le corresponde no indica la ubicación exacta y muchas veces simplemente se distribuyen de forma aleatoria dentro del polígono.
A continuación describiré por qué me parecio que este mapa era adecuado en el contexto de la discusión de la polarización política de la Ciudad de México. Luego mostraré cómo fue que hice este mapa (para esta parte se necesita tener conocimientos de Python y las librerías Numpy, Pandas y Geopandas). Por último finalizaré con algunas reflexiones sobre este ejercicio.
Motivación
Tras los primeros resultados de la jornada electoral del 6 de junio empezaron a circular varios mapas, mostrando los ganadores de las alcaldías en la Ciudad de México.

Estos mostraban que la ciudad quedó dividida en poniente/oriente por las dos principales fuerzas políticas. El poniente "de derecha" versus el oriente de "izquierda". Para quienes no conocen la CDMX, además hay un fuerte componente socioeconómico en esta división que se creó, como bien ha documentado Máximo Jaramillo. Se empezó a hablar del "muro de Berlín", pero entre meme y meme se empezó a asomar el clasismo/racismo de varios. Se empezaron a sacar conclusiones simplistas de que los del poniente son X, mientras los de oriente son Y.
Varios advirtieron que la división realmente no era tan dramática como parecía sugerir el mapa, porque en muchas alcaldías la victoria estuvo reñida. Pero eso no se podía ver en el mapa de la división, ahí solo cabe el ganador. Ese es un primer problema de los mapas coropléticos, no permiten mostrar más de una variable a la vez, para cada polígono solo podemos ver un solo valor (o color). Hay mapas bivariados, pero su alcance es limitado (y a mí personalmente no me gustan mucho). Mi primer objetivo entonces era poder mostrar que el voto no estaba totalmente inclinado hacia un lado u otro, sino que había diversidad en todas las alcaldías. Eso se puede mostrar usando otros tipos de gráficos, por ejemplo gráficos de barras, pero sentía que el impacto de los primeros mapas provenía de la división geográfica y que otro tipo de gráfica no reflejaba eso, entonces necesitaba un mapa para vencer a otro mapa. La división poniente/oriente existe, pero hay que dimensionarla en sus justas proporciones.
Un segundo problema de los mapas coropléticos es que el área causa una distorsión en la percepción porque las áreas más grandes sobresalen. Y en mapas de resultados electorales eso afecta mucho el mensaje, porque el dominio territorial de áreas grandes parece indicar mayor dominio político. El típico problema de "La tierra no vota, las personas sí". Enrique Tejada lo explica mejor en su blog.
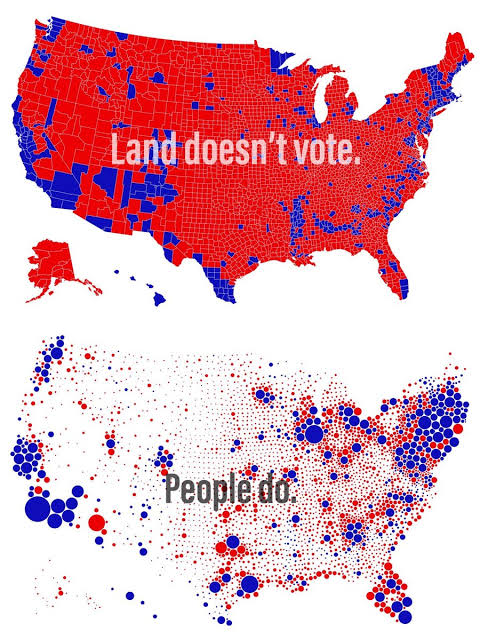
Con eso en mente, recordé que sensei Segasi había publicado alguna vez un mapa de puntos y me pareció que esa era una buena forma de representarlo: permitía mostrar la diversidad del voto y no exageraba la participación política de ningún partido. Sin embargo, los mapas de puntos normalmente distribuyen los puntos de manera aleatoria dentro del polígono, y eso me parece algo confuso, porque no permite dimensionar claramente qué partido tiene más o menos votos, además de que uno puede pensar que la ubicación del punto corresponde a una posición real, cuando no es así. Pensé entonces que necesitaba un mapa de puntos en el que yo pudiera definir la ubicación de los puntos de forma contigua para que fuera más fácil hacer comparaciones.
Esta forma de visualizar me parece tiene varias ventajas:
- Permite dimensionar la participación electoral: quiénes votaron y los que no.
- Permite ver la distribución del voto entre los distintos partidos dentro de cada alcaldía.
- Reduce sustancialmente el sesgo por tamaño de la alcaldía.
También es necesario ser conscientes de las desventajas o sesgos que puede haber en este tipo de mapa:
- No es adecuado si hay polígonos que son relativamente muy pequeños, porque no sería posible ver adecuadamente los puntos al interior. Por eso sería difícil hacer un mapa similar a nivel colonia o sección electoral.
- Las alcaldías más pequeñas pueden parecer que tienen más participación porque se ven más "rellenas" de puntos.
- La posición de los puntos no indica nada, pero es posible que algunos lo tomen como la ubicación de las casillas.
- El espacio en blanco sobrante (donde no hay puntos) puede confundirse con abstención.
Haciendo el balance, me parece que las ventajas son mayores a las desventajas para este problema particular.
Así fue como llegué a la idea del mapa, ahora el reto era hacerlo, porque hasta donde yo sabía no hay un programa o librería que los hiciera directamente. Me puse a experimentar con Python y llegué a lo que sigue a continuación.
Elaboración del mapa
Lo que sigue es bastante técnico y se requiere conocer bien las librerías más comunes de análisis de datos dentro del ecosistema de Python.
Lo primero que necesitamos para llegar al mapa de puntos (además de importar las librerías) es poder rellenar cada polígono con puntos. La idea a la que llegue para hacerlo es la siguiente:
- Obtener los bordes (inferior izquierdo, superior derecho) de cada polígono.
- Hacer una cuadrícula de puntos equidistantes usando los bordes.
- Seleccionamos solo los puntos de la cuadrícula que están contenidos por el polígono original.
Veamos paso a paso cómo se hace esto.
from math import ceil
import sys
import geopandas as gpd
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
print(sys.version)
print(pd.__name__, pd.__version__)
print(gpd.__name__, gpd.__version__)
print(np.__name__, np.__version__)
print(plt.matplotlib.__name__, plt.matplotlib.__version__)
Leemos el mapa de alcaldías de la CDMX. Se puede descargar aquí.
cdmx = gpd.read_file('datos/mapa_mexico/')\
.query('CVE_EDO=="09"')\
.set_index('CLAVE')
cdmx.boundary.plot()

Vamos a seleccionar solo una alcaldía para ilustrar el proceso
poly_index = '09005'
poly = cdmx.loc[poly_index, 'geometry']
poly
Obtengamos los bordes de este polígono:
x0, y0, x1, y1 = poly.bounds
print(x0, y0, x1, y1)
Vamos a crear una cuadrícula de puntos que estén separados a una distancia de 0.005 unidades decimales. Creamos la cuadrícula usando Numpy, luego la transformamos en un GeoDataframe para que sea posible hacer la unión espacial.
distancia = 0.005
# Cuadrícula de puntos
X, Y = np.meshgrid(np.arange(x0, x1, distancia), np.arange(y0, y1, distancia))
# lo convertimos en geodataframe
df_puntos_alc = pd.DataFrame(np.array([X.flatten(), Y.flatten()]).T, columns=['X', 'Y'])\
.assign(CLAVE=poly_index)\
.pipe(lambda df: gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df['X'], df['Y'])))
# así se ve
df_puntos_alc.plot()

¿Cómo sabemos cuáles de estos puntos caen dentro del área del polígono poly? Fácil, usamos el método .within de los GeodataFrames para saber cuáles están dentro.
df_puntos_alc = df_puntos_alc.loc[df_puntos_alc.within(poly)]
df_puntos_alc.plot()

Ahora lo hacemos para todas las alcaldías usando un loop. El resultado se guarda en el GeoDataframe df_xy
lista_df_puntos = list()
for poly_index in cdmx.index:
poly = cdmx.loc[poly_index, 'geometry']
x0, y0, x1, y1 = poly.bounds
x = np.arange(x0, x1, 0.005)
y = np.arange(y0, y1, 0.005)
X,Y = np.meshgrid(x, y)
df_puntos_alc = pd.DataFrame(np.array([X.flatten(), Y.flatten()]).T, columns=['X', 'Y'])\
.assign(CLAVE=poly_index)\
.pipe(lambda df: gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df['X'], df['Y'])))\
.loc[lambda df: df.within(poly)]
lista_df_puntos.append(df_puntos_alc.iloc[::-1])
df_xy = pd.concat(lista_df_puntos, axis=0)
df_xy.crs = {'init': 'epsg:4326'}
df_xy.tail()
Con esto cumplimos la primera parte. La siguiente es determinar cuántos votos debería representar cada punto. Para eso, necesito tener los resultados de la votación por alcaldía. Los datos los descargue del PREP. Así lucen:
prep_cdmx = pd.read_csv('datos/prep_cdmx/CDMX_ALC_2021.csv', header=4)
prep_cdmx.head(3)
Los resultados vienen a nivel casilla, así que hay que agregarlos por alcaldía. También hay que sumar los votos de las coaliciones y crear una variable que contenga la clave INEGI de cada municipio. Todo eso se hace a continuación:
dicc_alc_cve = {
'ALVARO OBREGON': '09010',
'AZCAPOTZALCO': '09002',
'BENITO JUAREZ': '09014',
'COYOACAN': '09003',
'CUAJIMALPA DE MORELOS': '09004',
'CUAUHTEMOC': '09015',
'GUSTAVO A. MADERO': '09005',
'IZTACALCO': '09006',
'IZTAPALAPA': '09007',
'LA MAGDALENA CONTRERAS': '09008',
'MIGUEL HIDALGO': '09016',
'MILPA ALTA': '09009',
'TLAHUAC': '09011',
'TLALPAN': '09012',
'VENUSTIANO CARRANZA': '09017',
'XOCHIMILCO': '09013'
}
alianza_pan = ['PAN', 'PRI', 'PRD', 'PAN_PRI_PRD', 'PAN_PRI', 'PAN_PRD', 'PRI_PRD']
alianza_morena = ['PVEM', 'PT','MORENA', 'PVEM_PT_MORENA', 'PVEM_PT', 'PVEM_MORENA', 'PT_MORENA']
prep_alc = prep_cdmx[alianza_morena + alianza_pan + ['TOTAL_VOTOS_ASENTADOS', 'LISTA_NOMINAL']].apply(pd.to_numeric, errors='coerce')\
.assign(alianza_pan_pri_prd=lambda x: x[alianza_pan].sum(axis=1),
alianza_morena_pt_pvem=lambda x: x[alianza_morena].sum(axis=1),
no_voto=lambda x: x['LISTA_NOMINAL']-x['TOTAL_VOTOS_ASENTADOS']
)\
.join(prep_cdmx['ALCALDIA'])\
.groupby('ALCALDIA', as_index=False).sum()\
.assign(CLAVE=lambda x: x['ALCALDIA'].map(dicc_alc_cve))
prep_alc.head()
Vamor ahora a unir los resultados de la votación con el GeoDataframe de las alcaldías de la ciudad.
cdmx = gpd.read_file('datos/mapa_mexico/')\
.query('CVE_EDO=="09"')\
.merge(prep_alc, on='CLAVE')\
.set_index('CLAVE')
cdmx.head(2)
El número de votos que vale cada punto es un parámetro clave que se establece un poco por ensayo y error, no hay un número predeterminado. En este post dan algunos consejos a tener en cuenta. Lo principal es que hay que cuidar el balance entre número y tamaño de los puntos para que ningún área se vea demasiado densa o que los puntos sean tan pequeños que no sea posible identificar claramente su color. Para encontrar el número aproximado de puntos lo que hice fue dividir el padrón electoral de cada alcaldía entre el número de puntos de la cuadrícula con forma de polígono. De entre todas las alcaldías me fijé en el valor mínimo. Eso garantiza que al menos para la delegación más pequeña habrá suficientes puntos para que toda su población esté representada. En este caso me dio que cada punto debería valer al menos 4217.3 votos. Cuaqluier valor por encima de eso nos serviría. Escogí finalmente 5,000 porque me parece que logra un buen balance entre visibilidad sin hacer que se vean áreas demasiado densas.
aprox_voto_punto = df_xy.groupby('CLAVE')[['Y']].count().join(cdmx[['TOTAL_VOTOS_ASENTADOS', 'no_voto']])\
.assign(voto_por_punto=lambda x: x['TOTAL_VOTOS_ASENTADOS'].add(x['no_voto']).div(x['Y']))\
.get('voto_por_punto').max()
print('Número aproximado de votos que debería valer cada punto', aprox_voto_punto)
voto_x_punto_participacion = 5000
print('Número de votos que vale cada punto seleccionado', voto_x_punto_participacion)
Lo que sigue ahora es determinar cuántos puntos en total deben quedarse en cada alcaldía, cuántos van a estar coloreados para cada coalición y las personas que no votaron. Hagámoslo para una delegación:
poly_index = '09005'
puntos_novoto = int(ceil(cdmx.loc[poly_index, 'no_voto'] / voto_x_punto_participacion))
puntos_morena = int(ceil(cdmx.loc[poly_index, 'alianza_morena_pt_pvem'] / voto_x_punto_participacion))
puntos_pan = int(round(cdmx.loc[poly_index, 'alianza_pan_pri_prd'] / voto_x_punto_participacion))
puntos_total_partidos = int(ceil(cdmx.loc[poly_index, 'TOTAL_VOTOS_ASENTADOS'] / voto_x_punto_participacion))
puntos_otros = puntos_total_partidos - puntos_morena - puntos_pan
print(puntos_novoto, puntos_morena, puntos_pan, puntos_otros)
Así tengo, por ejemplo, que en la alcaldía Gustavo A. Madero voy a usar en total 210 puntos distribuídos de la siguiente manera:
- 104 no votaron
- 50 a la coalición de MORENA, PT, PVEM
- 43 a la coalición de PAN, PRI, PRD
- 13 a otros partidos/candidatos independientes
Ya solo queda graficar. Así se va haciendo partido a partido:
fig, ax = plt.subplots()
cdmx.loc[[poly_index]].boundary.plot(color='k', ax=ax)
df_xy.query('CLAVE==@poly_index').iloc[:puntos_morena].plot(ax=ax, markersize=10, color='C3', label='Alianza MORENA-PT-PVEM')

df_xy.query('CLAVE==@poly_index').iloc[puntos_morena: puntos_morena + puntos_pan].plot(ax=ax, markersize=10, color='C0', label='Alianza PAN-PRI-PRD')
fig

df_xy.query('CLAVE==@poly_index').iloc[puntos_morena + puntos_pan: puntos_total_partidos].plot(ax=ax, markersize=10, color='gray', label='Otros')
fig

df_xy.query('CLAVE==@poly_index').iloc[puntos_total_partidos: puntos_total_partidos + puntos_novoto].plot(ax=ax, markersize=10, facecolor='yellow', edgecolor='gray', label='No votaron')
fig

Pues ya, un loop que lo haga para todas las alcaldías:
fig, ax = plt.subplots(figsize=(12, 12))
for poly_index in cdmx.index:
puntos_total_partidos = int(ceil(cdmx.loc[poly_index, 'TOTAL_VOTOS_ASENTADOS'] / voto_x_punto_participacion))
puntos_novoto = int(ceil(cdmx.loc[poly_index, 'no_voto'] / voto_x_punto_participacion))
puntos_morena = int(ceil(cdmx.loc[poly_index, 'alianza_morena_pt_pvem'] / voto_x_punto_participacion))
puntos_pan = int(round(cdmx.loc[poly_index, 'alianza_pan_pri_prd'] / voto_x_punto_participacion))
puntos_otros = puntos_total_partidos - puntos_morena - puntos_pan
cdmx.loc[[poly_index]].boundary.plot(color='k', ax=ax)
df_xy.query('CLAVE==@poly_index').iloc[:puntos_morena].plot(ax=ax, markersize=10, color='C3', label='Alianza MORENA-PT-PVEM')
df_xy.query('CLAVE==@poly_index').iloc[puntos_morena: puntos_morena + puntos_pan].plot(ax=ax, markersize=10, color='C0', label='Alianza PAN-PRI-PRD')
df_xy.query('CLAVE==@poly_index').iloc[puntos_morena + puntos_pan: puntos_total_partidos].plot(ax=ax, markersize=10, color='gray', label='Otros')
df_xy.query('CLAVE==@poly_index').iloc[puntos_total_partidos: puntos_total_partidos + puntos_novoto].plot(ax=ax, markersize=10, facecolor='yellow', edgecolor='gray', label='No votaron')
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[0:4], labels[0:4])
ax.set_axis_off()
ax.set_title('Voto a las alcaldías de la Ciudad de México, 2021', pad=5, fontsize=15)
ax.annotate(s=f'Nota: cada punto equivale a {voto_x_punto_participacion:,.0f} votos\nElaborado por @jjsantoso con datos del PREP, IECM', xy=(0, 50), xycoords='axes points', va='top', fontsize=10)
fig.savefig('graficas/voto_alcaldia_cdmx__participacion2021.png', dpi=600, bbox_inches='tight')

¡Listo!
Reflexiones finales
El mapa tuvo muy buen recibimiento y creo que la mayoría de personas entendió el mensaje que quería transmitir: la ciudad no está tan divida como nos decían que estaba. Algunos comentaron que era difícil conocer el total de votos de cada alcaldía, lo cual es cierto. Otros sugirieron otros tipos de análisis que se alejaban un poco del propósito inicial. Como en cualquier problema complejo, una sola visualización no puede ofrecer el panorama completo y es necesario acompañar cualquier análisis de más datos y distintos tipos de visualizaciones. Cada una puede mostrar una faceta del problema de estudio y juntas llegan a una conclusión mucho mejor.
Aunque por todo lo que dije antes parece que no me gustan los mapas coropléticos, eso no es para nada cierto, yo los uso mucho también. Cada mapa tiene su uso, depende del mensaje que se quiera transmitir. Debemos ser conscientes de las fortalezas y debilidades de cada forma de visualizar y ser cuidadosos para que, aunque tengamos las mejores intenciones, no terminemos mandando el mensaje equivocado.
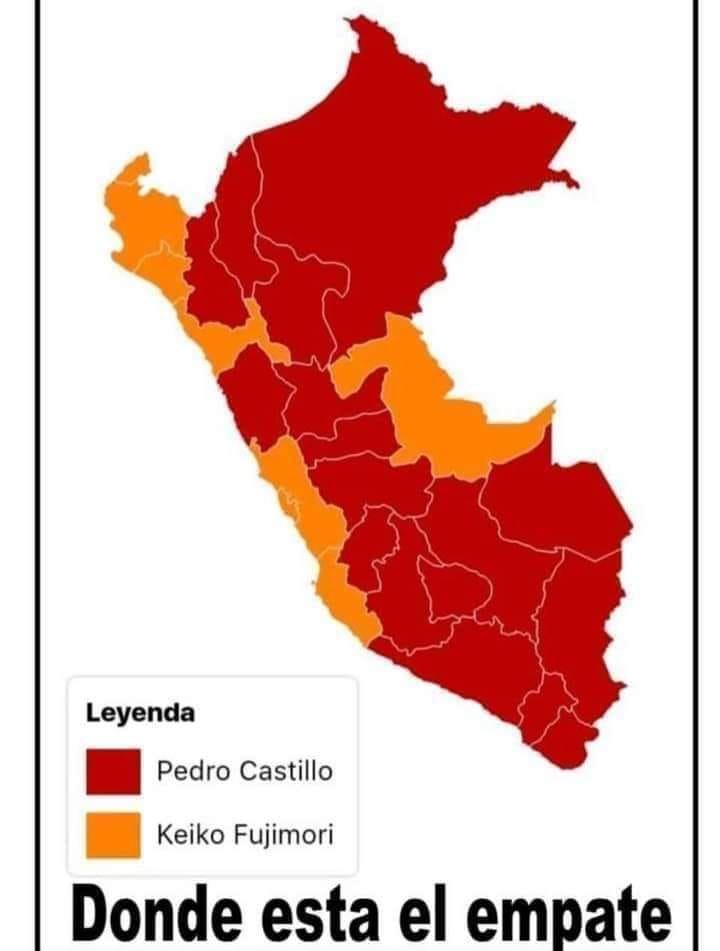
En las muy reñidas elecciones presidenciales de Perú anda circulando este mapa. ¿Qué les decimos?
Si les interesa hacer mapas en Python también escribí esta otra entrada en mi blog:
Revisa otras entradas de este blog:
- Integración de PyQGIS con Jupyter Lab usando Anaconda
- Introducción a PyQGIS (Python + QGIS)
- Introducción a bases de datos relacionales y SQL para científicos sociales
- Recuadros para mapas en Geopandas
- Etiquetado de variables y valores en las encuestas de INEGI usando Python
- Generando archivos de Excel con formatos y gráficas usando Python
- Trabajando con archivos de Excel complejos en Pandas