Etiquetado de variables y valores en las encuestas de INEGI usando Python
Para entender los datos de encuestas es necesario contar con un diccionario de variables y un catálogo de valores para las variables que se analizan. Organizar esta información puede ser un reto cuando estos metadatos vienen en archivos planos como `.csv`. Aquí muestro una aplicación usando datos de la ENSU de INEGI.
- Introducción
- Datos
- Uso de las etiquetas
- Si usas Stata...(o incluso si no)
- Revisa otras entradas de este blog:
Elaborado por Juan Javier Santos Ochoa (@jjsantoso)
Introducción
Hace poco me tocó trabajar con los datos de una encuesta de INEGI y usé Python para hacer el análisis descriptivo. Quienes trabajamos con datos del INEGI hemos visto que es usual que los archivos de datos abiertos vengan en varias carpetas que contienen tanto los datos como los metadatos e información adicional sobre la encuesta. Por ejemplo, si descargamos los datos para la Encuesta Nacional de Seguridad Pública Urbana (ENSU) veremos que vienen 3 carpetas, cada una corresponde a una sección de la encuesta:
-
conjunto_de_datos_VIV_ENSU_12_2020: Cuestionario sociodemográfico sección I y II -
conjunto_de_datos_CS_ENSU_12_2020: Cuestionario sociodemográfico sección III -
conjunto_de_datos_CB_ENSU_12_2020: Cuestionario principal de la encuesta sección I, II, III y IV
Si vemos al interior de uno de estos módulos, la estructura incluye las siguientes carpetas:
- Catálogos: tiene los catálogos para cada variable en el cuestionario
- Conjunto de datos: tiene los datos principales de la encuesta
- Diccionario de datos: el nombre e información de cada variable
- Metadatos: tiene información de la encuesta.
- Modelo entidad relación: es un diagrama que muestra cómo se relacionan los diferentes conjuntos de datos.
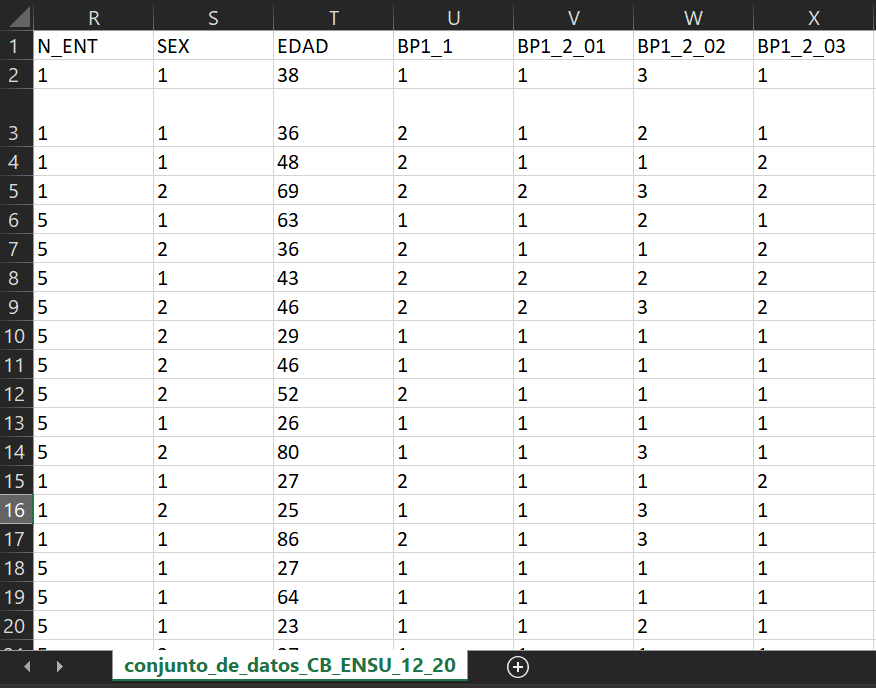
Si echamos un vistazo rápido a los datos en Excel (conjunto_de_datos/conjunto_de_datos_CB_ENSU_12_2020.csv) veremos que la mayor parte de las variables viene codificada. Solo con este archivo no podemos saber qué es cada columna y cuáles es el significado de sus valores. Nos hace falta el diccionario de variables y los catálogos para poder interpretarlas.
En el archivo diccionario_de_datos/diccionario_de_datos_CB_ENSU_12_2020.csv tenemos cuál es el texto de cada pregunta. De ahí sabemos que, por ejemplo, la pregunta BP1_1 es "Percepción de seguridad en la ciudad". Estos valores se conocen como etiquetas de las variables.
Por otro lado, dentro de la carpeta catalogos viene un archivo csv por cada variable del conjunto de datos.
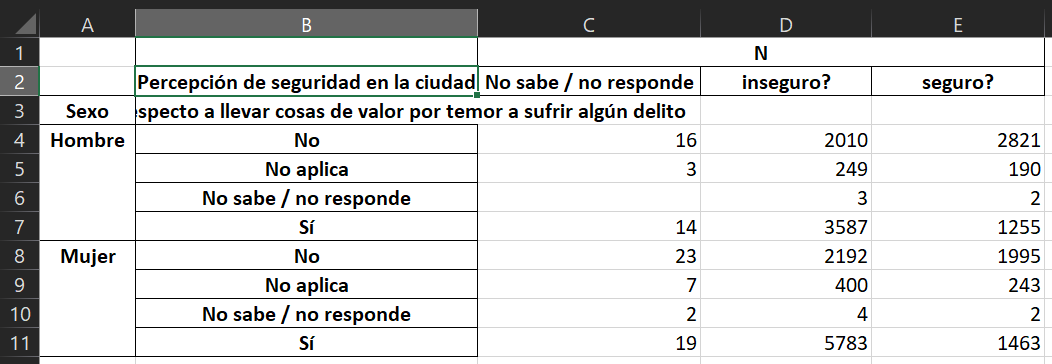
Este archivo nos dice cómo debemos transformar los valores numéricos de las categorías por sus valores de texto. Por ejemplo, si abrimos el archivo "BP1_1.csv" su contenido nos muestra que para la variable BP1_1 debemos interpretar que un 1 corresponde a la categorías "seguro?", el 2 corresponde a "inseguro?" y el 9 a "No sabe/No responde". Estos valores se conocen como etiquetas de los valores.

Es evidente que para manejar una encuesta es fundamental conocer las etiquetas de las variables y sus valores. Sería mucho más fácil si estas etiquetas estuvieran incluidas en el mismo archivo junto con los datos, pero como están en formato .csv no es posible guadar esa información en un solo archivo y por tanto, termina repartida en muchos. Entonces, nuestro objetivo es integrar el diccionario y el catálogo a los datos para que sea más fácil hacer nuestro análisis. Queremos que en las tablas o gráficas que hagamos, las variables categóricas aparezcan como texto, en lugar de los valores numéricos que asignó INEGI. De igual forma, nos gustaría que en lugar de aparecer el nombre de la variable como en la base de datos, aparezca su descripción. Para lograr esto usaremos objetos tipo diccionario nativos de Python y dataframes de Pandas.
.dta de Stata o .sav de SPSS sí permiten guardar esas etiquetas junto con los datos, sin embargo, esos no son formatos de datos abiertos que sean fácilmente accesible. En algunos casos, como en la ENOE, INEGI también publica archivos .dta y .sav.
Datos
Primero, vamos a importar las librerías necesarias.
import glob
import sys
import pandas as pd
print('Python', sys.version)
print(pd.__name__, pd.__version__)
Para ilustrar, vamos a seleccionar los datos de la carpeta conjunto_de_datos_CB_ENSU_12_2020 (Cuestionario principal de la encuesta sección I, II, III y IV).
datos = pd.read_csv('conjunto_de_datos_CB_ENSU_12_2020/conjunto_de_datos/conjunto_de_datos_CB_ENSU_12_2020.csv')
datos.head()
datos.info()
Necesitamos el diccionario de variables y los catálogos. Para el diccionario de variables cargamos el archivo conjunto_de_datos_CB_ENSU_12_2020/diccionario_de_datos/diccionario_de_datos_CB_ENSU_12_2020.csv
preguntas = pd.read_csv('conjunto_de_datos_CB_ENSU_12_2020/diccionario_de_datos/diccionario_de_datos_CB_ENSU_12_2020.csv', encoding='latin1')
preguntas.head(10)
Este nos muestra cómo aparece cada variable en el archivo de datos ("NEMONICO") y cuál es su descripción ("NOMBRE_CAMPO"), además contiene el tipo y rango de valores que puede tener cada variable. Por esta razón, el nombre de cada variable puede estar repetido varias veces. Lo que haremos es eliminar los duplicados y quedarnos con los valores únicos, para después crear un objeto diccionario que tenga como llaves el "NEMONICO" y como valores el "NOMBRE_CAMPO". A continuación se ve el proceso y el resultado:
dicc_preguntas = preguntas.drop_duplicates(subset=['NEMONICO']).set_index('NEMONICO')['NOMBRE_CAMPO'].to_dict()
print(str(dicc_preguntas)[:500])
Para el catálogo tenemos que trabajar un poco más porque la información está en muchos archivos. Primero vamos a generar una lista de todos los archivos en la carpeta catalogo.
dir_catalogos = 'conjunto_de_datos_CB_ENSU_12_2020/catalogos/'
archivos_catalogo_respuestas = glob.glob1(dir_catalogos, '*.csv')
archivos_catalogo_respuestas[:10]
A continuación vamos a leer cada uno de los archivos individuales y generar un diccionario por comprensión que contenga como llaves el "NEMONICO" y los valores serán otro diccionario que tiene la relación de los valores numéricos y de texto para los valores de cada variable.
dicc_respuestas = {
f[:-4]: pd.read_csv(f'{dir_catalogos}/{f}', encoding='latin1', index_col=f[:-4])['descrip'].to_dict() for f in archivos_catalogo_respuestas
}
print(str(dicc_respuestas)[:500])
Ahora tenemos dos diccionarios, uno con las etiquetas de las variables (dicc_preguntas) y otro con las etiquetas de los valores de cada pregunta dicc_respuestas. En ambos diccionarios la llave principal es el némonico de la pregunta, por tanto si queremos saber cuáles son las etiquetas de variables y valores solo tenemos que indexar los diccionarios con el nemónico correspondiente, por ejemplo para "SEX" y "BP1_1" obtenemos:
print('Etiqueta de variable:', dicc_preguntas['SEX'], '\nEtiqueta de valores',dicc_respuestas['SEX'])
print('Etiqueta de variable:', dicc_preguntas['BP1_1'], '\nEtiqueta de valores',dicc_respuestas['BP1_1'])
Uso de las etiquetas
Ya que tenemos las etiquetas, veamos cómo podemos usarlas para interpretar mejor en nuestros análisis. Hagamos una tabulación cruzada para ver la distribución de respuestas de las variables "SEX" y "BP1_1"
FAC_SEL) por tanto los resultados no son estimaciones válidas. En una próxima entrada veremos cómo integrar las ponderaciones.
pd.crosstab(datos['SEX'], datos['BP1_1'])
El índice del dataframe y los nombres de las columnas contienen los valores numéricos de las categorías. Vamos a reemplazarlos por sus valores de texto renombrándolo con el método .rename()
pd.crosstab(datos['SEX'], datos['BP1_1'])\
.rename(index=dicc_respuestas['SEX'],
columns=dicc_respuestas['BP1_1'])
Ahora es mucho más fácil de entender esta tabla.
Vamos a hacer otra tabla similar a la anterior, pero en este caso desagregando por más variables y usando el método groupby:
vars_by = ['SEX', 'BP1_1', 'BP1_5_1']
grouped = datos.groupby(vars_by).agg(N=('ID_PER', 'count'))
grouped.head(15)
Nuevamente reemplazamos los valores de las categorías usando el método .rename(). Hacemos un loop para reemplazar las categorías de cada variable. Como tenemos varios niveles en el índice, especificamos la opción level para que use solo el catálogo con la variable que le corresponde.
for v in vars_by:
grouped.rename(index=dicc_respuestas[v], level=v, inplace=True)
grouped
Para que sea más fácil de ver, reestructuramos la tabla usando .unstack().
grouped.unstack('BP1_1')
Ya integramps las etiquetas de los valores, ahora faltan las etiquetas de las variables. Para eso usaremos el método .rename_axis()
cuadro = grouped.unstack('BP1_1')\
.rename_axis(index=dicc_preguntas, columns=dicc_preguntas)
cuadro
Nuestro cuadro ya es entendible, podemos exportarlo a Excel y verificar que tenemos las etiquetas:
cuadro.to_excel('reporte.xlsx')
Si usas Stata...(o incluso si no)
Como dije antes, el formato .dta permite guardar las etiquetas de variables y valores junto con los datos. Los DataFrames de Pandas traen de forma nativa el método .to_stata() para exportar la información a este formato. Para que Stata reconozca correctamnete las etiquetas de valores es necesario que en pandas las variables sean de tipo categoria. A continuación, vamos a seleccionar un subconjunto de variables, reemplazaremos sus valores numéricos por las categorías de texto y convertiremos la variable en tipo categórica:
vars_export = ['SEX', 'BP1_1', 'BP1_2_01', 'BP1_2_02', 'BP1_2_03', 'BP1_2_04', 'BP1_2_05', 'BP1_2_06', 'BP1_2_07', 'BP1_2_08', 'BP1_2_09', 'BP1_2_10', 'BP1_2_11', 'BP1_2_12']
datos_stata = datos[vars_export].apply(lambda s: s.map(dicc_respuestas[s.name])).astype('category')
datos_stata
Este dataframe lo exportaremos a Stata, junto con el diccionario que contiene las etiquetas de variables, especificando en la opción variable_labels.
datos_stata.to_stata('datos_stata.dta', write_index=False, variable_labels=dicc_preguntas)
Al abrir el arcivo en Stata podemos ver que efectivamente se guardaron las etiquetas de los valores y de las variables:
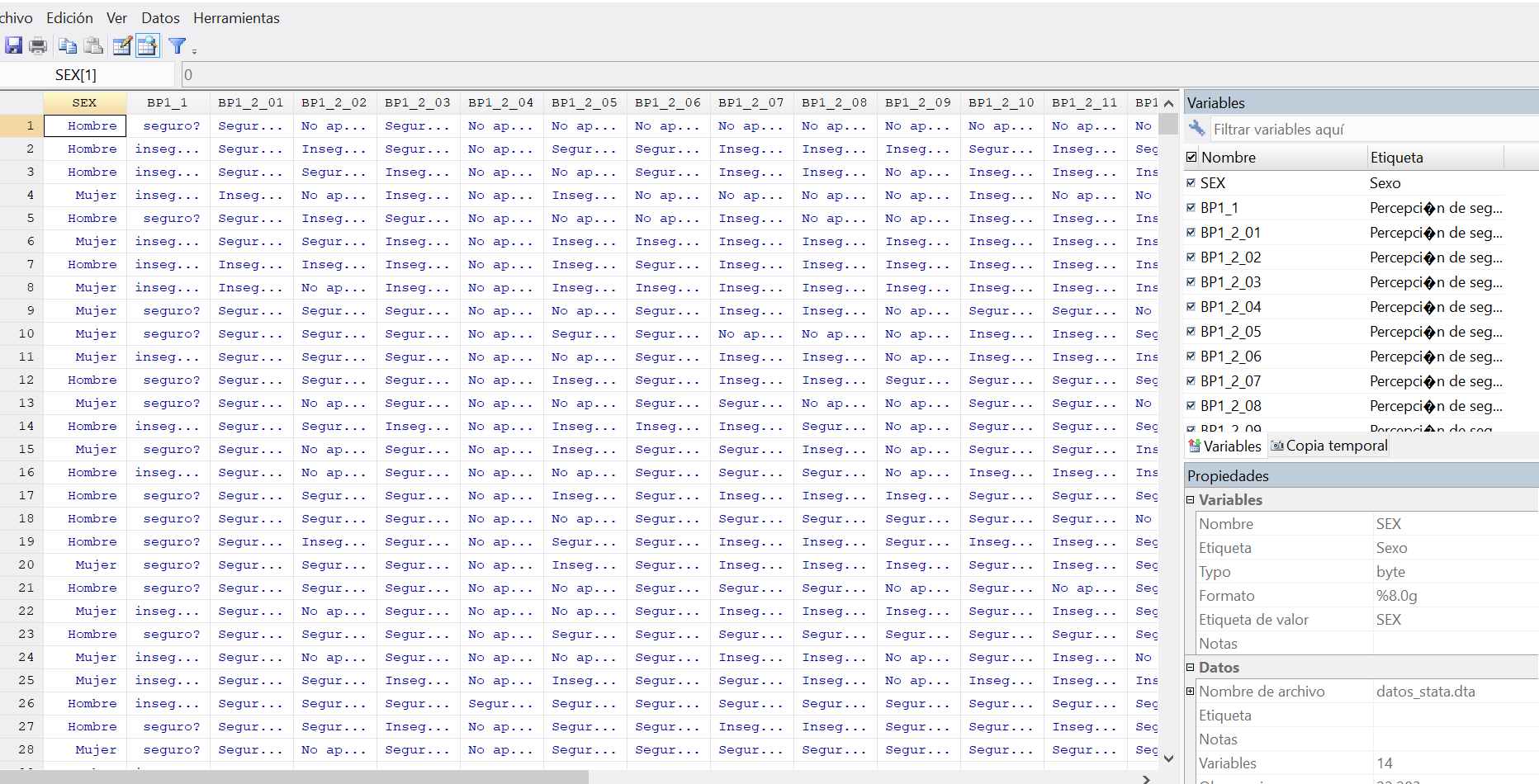
Hasta donde entiendo, esta sería una forma más fácil de etiquetar datos provenientes de INEGI para usuarios de Stata que haciendo el procedimiento entero en Stata. Igualmente, para los que no son usuarios de Stata, pero sí de Python o R y quieren conservar las variables categóricas etiquetadas este es un buen formato.
datos_2 = pd.read_stata('datos_stata.dta')
datos_2.dtypes
Revisa otras entradas de este blog:
- Integración de PyQGIS con Jupyter Lab usando Anaconda
- Introducción a PyQGIS (Python + QGIS)
- Mapas de puntos con Python
- Introducción a bases de datos relacionales y SQL para científicos sociales
- Recuadros para mapas en Geopandas
- Generando archivos de Excel con formatos y gráficas usando Python
- Trabajando con archivos de Excel complejos en Pandas