Introducción a bases de datos relacionales y SQL para científicos sociales
Conceptos fundamentales para entender qué es SQL y por qué deberíamos usarlo
- Introducción
- Limitantes de la forma usual de trabajar
- Sistemas de administración de bases de datos.
- SQLite
- Consultas SQL
- Funciones y operaciones con columnas
- Agregaciones y agrupaciones
- Uniones
- Referencias
- Revisa otras entradas de este blog:
En ciencias sociales trabajamos mucho con datos para hacer investigación cuantitativa. Casi siempre, nuestros inicio en el manejo de datos se da en cursos de estadística, por lo que las funciones que necesitamos aprender son leer, procesar y reestructurar datos para luego visualizar variables y estimar modelos estadísticos. Como parte de nuestra práctica, normalmente guardamos la información en formatos de archivos como XLSX (Excel), CSV (comma separated values), TXT (texto plano), DTA (Stata), SAV (SPSS), Rdata (R) y trabajamos con Software de análisis de datos como Stata, R, SPSS, Python, SAS, entre otros. Además, solemos estructurar nuestra información de forma tal que toda quede en una única tabla. Llamemos a estas practicas como la "forma usual de trabajar".
Esta forma usual de trabajar tiene ventajas para nosotros porque nos facilita concentrarnos en procesar y analizar datos, en lugar de preocuparnos por la administración de la información. La mayoría de las veces se trata de tareas que solo ejecutaremos unas pocas veces en nuestra computadora y en las que no es necesario que otras personas puedan acceder a nuestros datos. Además, suele ser información que no se actualiza de forma continua y de una escala relativamente pequeña. Sin embargo, cuando nos enfrentamos a alguna de las situaciones que acabdo de describir anteriormente, ya no es tan conveniente seguir este flujo de trabajo. Pese a que existen desde hace mucho otras formas de trabajar cuando el proceso de manejo de datos se vuelve más complejo, normalmente desconocemos por completo otras alternativas. Una de esas alternativas son las bases de datos relacionales.
A lo largo de esta sesión veremos cuáles son las situaciones en las que podemos considerar el uso de base de datos relacionales, cuáles son sus características y cómo podemos consultarlas. Empecemos primero viendo con un poco más de detalles las limitantes en la forma usual de trabajar .
-
Dificultad para leer y actualizar los datos: Los archivos planos (csv, txt) o binarios (Excel, Rdata, dta, etc) son difíciles de leer y actualizar. Siempre que se leen se debe abrir el archivo completo, aunque solo se necesite trabajar con unas pocas observaciones. Además, para agregar nuevos registros se requiere primero cargar todos los datos en memoria y luego volverlos a escribir nuevamente al disco, lo que es un proceso computacionalmente muy costoso.
-
Imposibilidad para modificar por varios usuarios: Estos archivos normalmente solo están disponibles de forma local (en nuestra computadora), por lo que solo pueden ser usados por un usuario a la vez. Una vez un usuario hace modificaciones, es difícil mantener a los demás usuarios con la información actualizada. Aún peor, si varios usuarios modifican los datos de forma individual, luego es muy difícil conciliar las diferentes versiones. Si bien existen alternativas en la nube (hojas de cálculo de Google, Excel online), estas están diseñadas para trabajar de forma interactiva, no programática.
-
No hay validación de datos: no hay una forma fácil de validar o aplicar restricciones sobre los datos nuevos que se ingresan en la base de datos. Una validación puede ser, por ejemplo, si tengo una variable numérica, no puedo guardar ahí un dato que es de texto, u otro ejemplo es verificar que un nuevo valor que voy a ingresar esté dentro de un catálogo de opciones predeterminadas.
-
Falta de autenticación y permisos: no hay mecanismos para controlar qué usuarios pueden acceder a la información y qué facultades tienen para modificarla.
-
No asegura atomicidad de las transacciones : La atomicidad se refiere a que al hacer un conjunto de operaciones en una base de datos, ante un fallo el resultado no puede quedar a medias, el proceso se hace completo o no se hace nada.
-
Los datos deben caber en memoria RAM: la mayoría de software estadísticos deben leer los datos y guardarlo en la memoria RAM para poder trabajar con ellos, por lo que hay un límite sobre la cantidad de información que se puede analizar.
-
Redundancia: cuando se intenta que toda la información de un proyecto esté en una sola tabla de datos, muchas veces es necesario repetir la información.
Todas estas limitaciones pueden ser abordadas usando sistemas de administración de bases de datos.
Antes que nada, hay que aclarar algo. En ciencias sociales le llamamos base de datos a cualquier archivo que contenga datos, pero tecnicamente esto no es correcto. Los ingenieros de sistemas entienden algo más complejo cuando se habla de bases de datos. Hay cierta ambiguedad en el término, pero cuando hablamos de bases de datos normalmente hacemos referencia a los Sistemas de Administración de Bases de Datos (DBMS, por sus siglas en inglés) que son sitemas que simplifican la administración de los datos de una forma organizada y consistente. Otras veces el término base de datos puede hacer referencia a un conjunto de datos guardado en un DBMS. Aunque se suelen usar indistintamente, tratemos de dar una definción a cada concepto:
-
Base de datos: es una colección estructurada de datos sobre entidades y sus relaciones. Modela objetos de la vida real -entidades y relaciones- y captura su estructura en formas que permiten que estas entidades y relaciones puedan ser consultadas para hacer análisis.
-
Sistema de administración de bases de datos (DBMS): es un software diseñado para guardar bases de datos de forma segura y manejarlas eficientemente, además de cumplir con otras tareas de mantenimiento y consulta de las entidades y relaciones que la base de datos representa. Hay muchos tipos de DBMS que tienen funciones especiales para diferentes casos de uso.
En una base de datos relacional tenemos tablas que representan distintas entidades y relaciones que indican relaciones entre los objetos guardados en las tablas.
- Una tabla es un arreglo en filas y columnas, donde cada fila representa una observación y cada columna es un atributo de las observaciones. Es como una hoja de excel.
- Las columnas, también conocidas como campos, tienen un nombre y un tipo, que indica el tipo de información que se puede guardar (número, texto, fecha, etc). Todos los datos de una columna deben ser del mismo tipo.
- Toda tabla debería tener una columna que es conocida como la llave primaria (primary key o PK) que debe tener un valor único dentro de la tabla y permite identificar a cada observación. Usualmente es un número entero.
- Las relaciones son vínculos entre un objeto de una tabla y uno o varios objetos en otras tablas.
- La relación entre tablas permite guardar estructuras de datos muy complejas de forma mucho más sencillas.
- Hay varios tipos de relaciones: uno a uno, uno a muchos y muchos a muchos.
- Cuando se crea una relación se genera un llave externa (Foreign Key o FK) en la tabla.
A la información que comprende las tablas, los campos de las tablas junto con el tipo de dato y las relaciones entre las tablas se le conoce como el esquema de la base de datos. Toda esta información se puede de comprender de forma mucho más fácil mediante un diagrama conocido como diagrama Entidad-Relación.
Es muy importante cuando se trabaja con una base de datos pensar en cada tabla como una entidad, esto es como si fuera el objeto independiente más sencillo con el que podemos trabajar, y luego crear las relaciones entre las entidades.
Como ejemplo de estos conceptos pensemos en una escuela donde se ofrece cursos a los alumnos, y estos cursos son dictados por profesores. Tenemos entonces tres entidades: cursos, profesores y estudiantes. Cada una de estas entidades es una tabla que tiene distintos atributos y además hay una relación clara entre ellas: todo curso tiene un profesor y uno o varios alumnos. El diagrama entidad-relación es el siguiente:
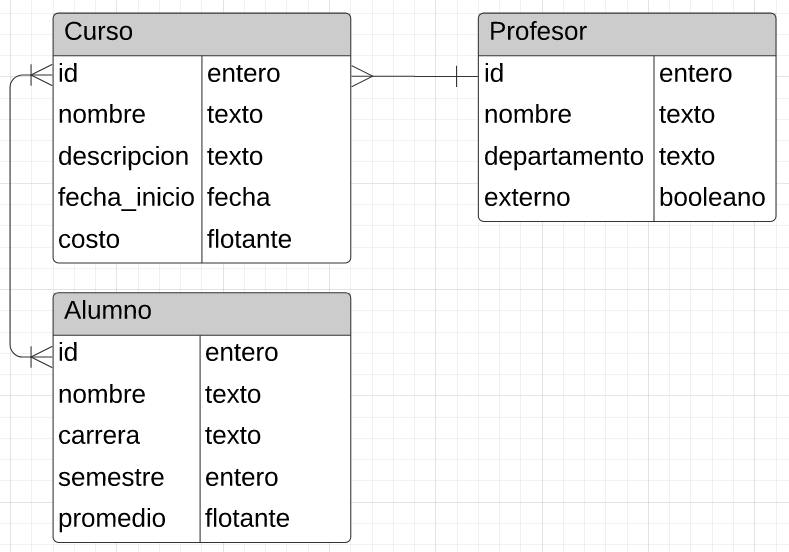
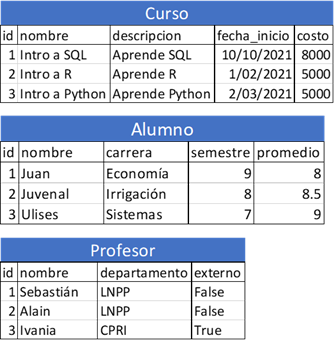
Las tablas con los datos se verían de la siguiente manera:
SQL (pronunciado como sicuel o ese-cu-ele) es un lenguaje para manejar bases de datos. Sirve para crear, modificar y eliminar bases de datos, tablas, campos, datos, así como también para consultar los elementos dentro de una base de datos. SQL es realmente un estándar, ya que cada DBMS tiene su propio lenguaje y funciones, sin embargo, casi todas las bases de datos relacionales soportan las características básicas de SQL, aunque con ligeras variaciones.
Este tutorial trataremos más adelante cómo hacer consultas de información con SQL. En otro se tratará la definición de bases de datos.
Los DBMS se suelen clasificar en dos grandes grupos: SQL y NoSQL. Cuando los datos con los que trabajamos son estructurados es decir, tienen un equema que puede ser facilmente representados en tablas con filas y columnas, entonces se usan DBMS relacionales conocidos como SQL. Entre los más populares están:
- SQLite
- MySQL
- PostgreSQL
- MariaDB
- Oracle Database.
- Google BigQuery
Por otro lado, existen otros DBMS conocidos como NoSQL (Not only SQL) que son adecuados cuando los datos son no estructurados, es decir no tienen una estructura definida y cada observación puede constar de distintos campos y de tipos de datos mucho más complejos. Normalmente se usan cuando se trata de bases de datos muy grandes o que representan datos especiales, como por ejemplo las redes. Estas bases de datos suelen tener sus propios lenguajes de consulta, diferentes a SQL. Entre las más populares están:
- MongoDB
- Neo4J
- Cassandra
- Redis
La decisión sobre qué tipo de base de datos es la mejor dependerá siempre del proyecto específico en el que se trabaje y las tareas que se requieran. En este tutorial usaremos SQLite.
Si hemos estudiado alguna carrera de ciencias sociales, probablemente nos costará trabajo empezar a crear y administrar nuestras propias bases de datos porque hay reglas y protocolos para los que se requiere mucha práctica para aprender a ejecutar correctamente. El diseño y puesta en producción de una base de datos debe hacerlo alguien con experiencia.
Aún cuando puede ser cierto que nosotros nunca vayamos a crear una base de datos desde cero, es necesario que aprendamos los fundamentos de las bases de datos por varias razones.
- El modelo relacional es una forma poderosa de organizar la información.
- Cada vez es más común el uso de SQL dentro de proyectos de ciencia de datos.
- Si alguna vez tienes que proveer datos para un sistema de base de datos, podrás entender mejor cómo pasar la información al encargado de su administración.
- Si entiendes sus ventajas podrás recomendarlo en los casos en que es conveniente su uso.
Sobre este último punto, deberíamos optar por usar un DBMS en cualquiera de las siguientes situaciones:
- Requerimos consultar o actualizar los datos de forma constante.
- Los datos deben ser consultados o editados por varios usuarios de forma remota.
- Tenemos información que está en muchos archivos pero que está relacionada, y que ademas debe cumplir con ciertas restricciones, como asegurar que los valores pertenezcan a un catálogo.
- Necesitamos analizar datos muy grandes que no caben en memoria RAM.
- Cuando creamos un producto basado en datos para producción, por ejemplo páginas web o aplicaciones de escritorio.
- Necesitamos autenticación de usuarios y/o diferentes permisos para administrar los datos.
- Cuando necesitamos garantizar atomicidad.
SQLite
La mayor parte del contenido de aquí en adelante fue tomado de:Data Management with SQL for Social Scientists
En este tutorial veremos una corta introducción a los comandos más comunes para consultar la información de una base de datos. Hacer consultas es una tarea relativamente sencilla que todos deberíamos aprender.
Para esto usaremos SQlite, que es un DBMS sencillo, adecuado para aplicaciones locales que requieren tipos de datos básicos y pocas funciones avanzadas. No provee un sistema de autenticación y permisos y tampoco soporta escritura de varias conexiones al mismo tiempo, pero es fácil de iniciar y ayuda a mostrar las principales características del lenguaje de consulta. Aunque no es adecuado para aplicaciones empresariales, puede ser buena opción para hacer análisis de datos.
Los clientes son programas que permiten conectarse a bases de datos y efectuar operaciones sobre ellas a través de una interfaz de usuario.
Usaremos el cliente DB Browser for SQLite una aplicación ligera que puede ser descargada desde su página web: https://sqlitebrowser.org/dl/
Una vez instalado se puede buscar en los programas como DB Browser (SQLite).
- Usaremos una base de datos sobre cultivos del proyecto SAFI (Studying African Farmer-led Irrigation). Los datos vienen en el archivo "SQL_SAFI.sqlite", que también puede ser descargado desde https://datacarpentry.org/sql-socialsci/data/SQL_SAFI.sqlite. Esta base de datos consta de 4 tablas que describen un conjunto de granjas (Farms), parcelas (Plots) y cultivos (Crops & crops_rice_old).
- Vamos al cliente y hacemos clic en el botón de "Open Database". Buscamos en nuestros archivos y seleccionamos ""SQL_SAFI.sqlite""
- Cuando se abre, en la pestaña "Database Structure" veremos lo siguiente:
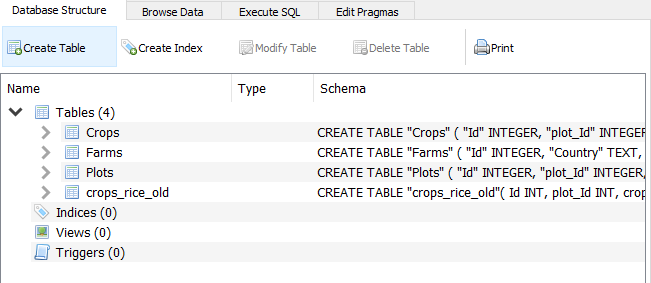
- Tenemos 4 tablas: Crops, Farms, Plots y crops_rice_old.
- Si damos clic sobre las $>$ de cada tabla podremos ver los campos que tiene cada una y su tipo:
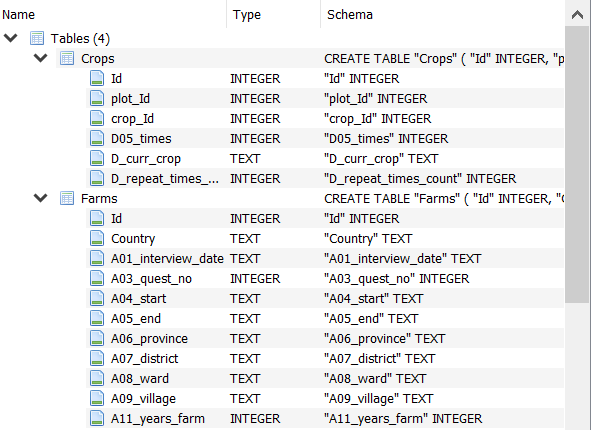
- Al seleccionar la pestaña "Browse Data" se puede ver la tabla con los datos.
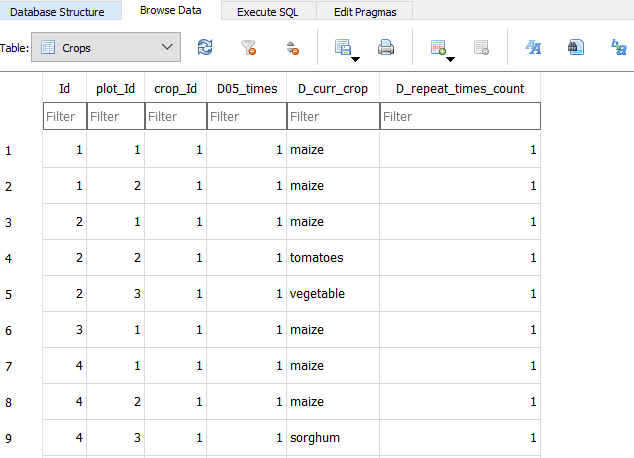
- Para consultar la información usamos el lenguaje SQL.
- Toda consulta SQL debe llevar al menos dos comandos: SELECT y FROM
- con SELECT especificamos las columnas que queremos recuperar
- con FROM especificamos la tabla que vamos a consultar
Un ejemplo de consulta es:
SELECT *
FROM Crops
- Los comandos de SQL normalmente se escriben en mayúsculas, aunque no es necesario, pero así se distingue mejor cuáles con los comandos de los nombres las variable o tablas.

- Tampoco es necesario escribirlos en líneas separadas, pero se hace más legible así.
- Vamos a la pestaña "Execute SQL" de DB Browser y copiamos el siguiente código:
SELECT * FROM Crops
- La instrucción se ejecuta con el botón ▶ del menú.
Obtenemos como resultado una tabla con todas las filas y columnas de la tabla Crops:
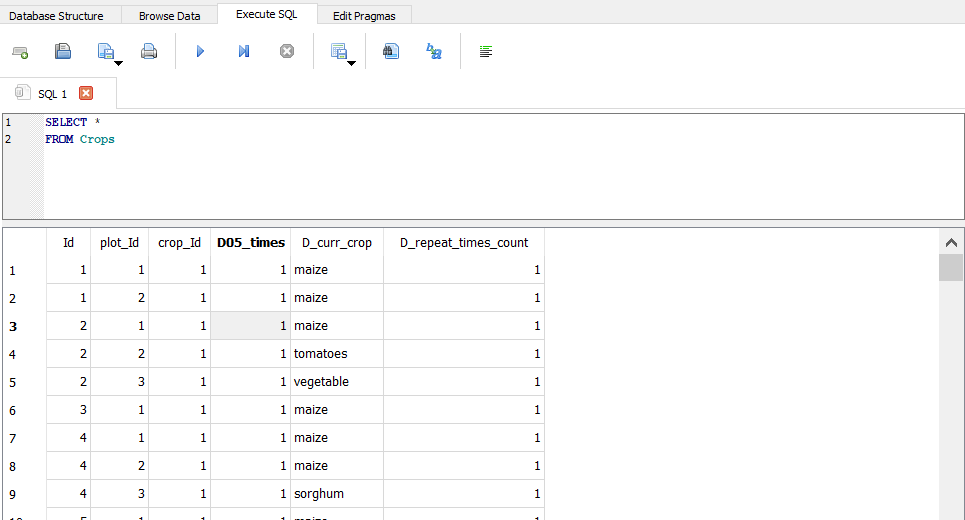
- El resultado de una consulta SQL siempre es una tabla.
- A continuación veremos los comandos más populares para consultar la información.
- Puedes seguir este tutorial usando DB Browser o también si tienes instalada la distribución de Python de Anaconda, puedes instalar la extensión ipython-sql que permite ejecutar SQL dentro de un Jupyter Notebook.
- Si sigues en DB browser, debes copiar el código de cada celda sin la primera fila (%%sql)
# Esta instrucción solo funciona dentro de un Jupyter Notebook
# pip install ipython-sql
%load_ext sql
%sql sqlite:///SQL_SAFI.sqlite
%config SqlMagic.displaylimit=10
- Con SELECT especificamos los nombres de las columnas que queremos que nos retorne la consulta.
- Podemos especificar uno o varios nombres de columnas, separados por comas.
- El * quiere decir que retorne todas las columnas.
%%sql
SELECT id, Country, A06_province
FROM Farms
- Las variables pueden ser renombrar en el resultado usando la palabra AS
%%sql
SELECT Country AS pais, A06_province AS provincia
FROM Farms
- Especifica el número máximo de filas a retornar
%%sql
SELECT *
FROM Farms
LIMIT 5
WHERE
- Este comando sirve para imponer una o varias condiciones. El resultado retornará solo las observaciones que cumplan con los criterios especificados.
- Se pueden usar operadores como $=$, $>$, $<$, $<=$, $>=$, $<>$
- Para especificar más de una condición se pueden usar los operadores lógicos AND y OR
%%sql
SELECT Id, B16_years_liv
FROM Farms
WHERE B16_years_liv > 25
- Varias condiciones
%%sql
SELECT Id
FROM Farms
WHERE B17_parents_liv = 'yes'
AND B18_sp_parents_liv = 'yes'
AND B19_grand_liv = 'yes'
AND B20_sp_grand_liv = 'yes'
%%sql
SELECT Id, B16_years_liv
FROM Farms
WHERE B16_years_liv > 50 AND B16_years_liv < 60
- Se puede usar el operador BETWEEN para especificar un rango de valores.
%%sql
SELECT Id, B16_years_liv
FROM Farms
WHERE B16_years_liv BETWEEN 51 AND 59
- Se puede usar el operador IN para especificar una lista de valores.
%%sql
SELECT Id, B16_years_liv
FROM Farms
WHERE B16_years_liv IN (51, 52, 53, 54, 55, 56, 57, 58, 59)
- Al poner varias condiciones, es recomendable agruparlas con paréntesis para evitar confusiones.
%%sql
SELECT Id
FROM Farms
WHERE (B17_parents_liv = 'yes' OR B18_sp_parents_liv = 'yes') AND B16_years_liv > 60
Práctica
- Escribe una consulta con la tabla
Farmsque retorne las columnasId,A09_village,A11_years_farm,B16_years_liv. Filtra las filas para quedarnos solo con las filas donde el valor deA09_villageesGodoRuaca. Adicionalmente, solo queremos valores deA11_years_farmentre 20 y 30 y valores deB16_years_livmayores que 40.
- Para seleccionar observaciones que tienen valores nulos se usa la condición IS NULL.
- Para seleccionar los que son no nulos se usa IS NOT NULL
%%sql
SELECT B16_years_liv, F14_items_owned
FROM Farms
WHERE F14_items_owned IS NULL
%%sql
SELECT B16_years_liv, F14_items_owned
FROM Farms
WHERE F14_items_owned NOT NULL
%%sql
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village = 'God'
ORDER BY A11_years_farm
- Se puede especificar el orden ascendente o descendente con ASC o DESC, respectivamente.
%%sql
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village = 'God'
ORDER BY A11_years_farm DESC
- Se puede ordenar por varias variables
%%sql
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village = 'God'
ORDER BY A11_years_farm ASC , B16_years_liv DESC
- En conjunto con LIMIT nos puede dar el top N
%%sql
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village = 'God'
ORDER BY A11_years_farm DESC
LIMIT 3
- Es posible hacer algunas operaciones aritméticas entre columnas
%%sql
SELECT B16_years_liv * 100
FROM Farms
%%sql
SELECT B_no_membrs * B16_years_liv AS total_years
FROM Farms
- También se pueden usar funciones predeterminadas que transforman las variables. Hay funciones para números, para texto, para fechas, etc.
- La lista de funciones que se puede usar en SQLite están se pueden consultar en https://sqlite.org/lang_corefunc.html
- Por ejemplo, la función ROUND() redondea los valores de una columna.
%%sql
SELECT ROUND(D02_total_plot * 3.14159, 1) AS D02_rounded
FROM Plots
- La función SUBSTR() sirve para obtener un subconjunto de caracteres de un texto, dada una posición inicial y un número de caracteres.
- La expresión CAST(variable AS INTEGER) convierte una variable de texto en número entero.
%%sql
SELECT CAST(SUBSTR(A01_interview_date,7,4) AS INTEGER) AS year
FROM Farms
ORDER BY A01_interview_date
- La expresión $||$ concatena dos variables de texto.
%%sql
SELECT A12_agr_assoc || ' & ' || B11_remittance_money AS assoc_remittance
FROM Farms
- Cuando se requiere ordenar por una fecha, es necesario convertir el texto en fecha, de lo contrario tendremos un orden que no es el adecuado.
- Se puede usar la función DATE() para pasar de texto a fecha. Para ello es necesario especificar el texto en formato YYYY-MM-DD.
- En el siguiente ejemplo, la variable
A01_interview_dateestá guardada como texto en formato dd/mm/yyy, por tanto, cuando intentamos ordenar por esta variable obtenemos un orden distinto al que esperaríamos.
%%sql
SELECT A01_interview_date
FROM Farms
ORDER BY A01_interview_date
- En este caso lo que deberíamos hacer es reformar el texto para que quede en formato yyyy-mm-dd y usar la función DATE() para convertir en fecha.
%%sql
SELECT A01_interview_date,
date(
substr(A01_interview_date,7,4) || '-' ||
substr(A01_interview_date,4,2) || '-' ||
substr(A01_interview_date,1,2)
) AS converted_date
FROM Farms
ORDER BY converted_date
- Con la expresión CASE ... WHEN ... podemos cambiar los valores de una variable por otros al momento de presentar la información
%%sql
SELECT Id, B16_years_liv,
CASE country
WHEN 'Moz' THEN 'Mozambique'
WHEN 'Taz' THEN 'Tanzania'
ELSE 'Unknown Country'
END AS country_fullname
FROM Farms
%%sql
SELECT Id, A11_years_farm,
CASE
WHEN A11_years_farm BETWEEN 1 AND 30 THEN '1-30'
WHEN A11_years_farm BETWEEN 31 AND 60 THEN '31-60'
ELSE '> 60'
END AS A11_years_farm_range
FROM Farms
- Podemos seleccionar los valores únicos de una o varias columnas con la expresión DISTINCT.
%%sql
SELECT DISTINCT A06_province
FROM Farms;
%%sql
SELECT DISTINCT A06_province, A07_district
FROM Farms
- Una de las características más útiles de SQL es la capacidad para calcular algunas estadísticas agregadas.
- Para agregar se usan algunas funciones como COUNT(), MAX(), MIN(), AVG()
%%sql
SELECT COUNT(A11_years_farm) AS n, MAX(A11_years_farm) AS maximo, MIN(A11_years_farm) AS minimo, ROUND(AVG(A11_years_farm), 2) as promedio
FROM Farms
- Podemos calcular estadísticas agrupadas usando la expresión GROUP BY
%%sql
SELECT
A06_province, A07_district, A08_ward, A09_village,
COUNT(A11_years_farm) AS n, MAX(A11_years_farm) AS maximo, MIN(A11_years_farm) AS minimo, ROUND(AVG(A11_years_farm), 2) as promedio
FROM Farms
GROUP BY A06_province, A07_district, A08_ward, A09_village
- Para filtrar los resultados de una consulta agregada usamos la declaración HAVING
%%sql
SELECT
A06_province, A07_district, A08_ward, A09_village,
COUNT(A11_years_farm) AS n, MAX(A11_years_farm) AS maximo,
MIN(A11_years_farm) AS minimo, ROUND(AVG(A11_years_farm), 2) as promedio,
SUM(A11_years_farm) as total
FROM Farms
GROUP BY A06_province, A07_district, A08_ward, A09_village
HAVING promedio > 20
Práctica
- Usando la tabla
Plots, calcula la extensión total y número de parcelas de cada granja.Ididentifica cada granja yD02_total_plotes la extensión de cada parcela individual. - Filtra para quedarte solo con aquellas granjas que tienen más de 10 hectáreas en total y además entre 2 y 3 parcelas.
- Hasta el momento hemos estado usando datos de una sola tabla, pera para muchos casos quisieramos responder preguntas que involucren los datos de más de una tabla.
- Cuando queremos usar los datos de más de una tabla debemos hacer uniones con el comando JOIN. Esta unión se hace en la declaración FROM.
- En la siguiente consulta queremos saber en cuáles granjas con más de 12 miembros se cultiva maíz. La información del número de miembro de la granja está en la tabla Farms, pero la información del tipo de cultivo está en la tabla Crops. Por tanto, debemos hacer un JOIN entre las dos tablas.
- Cuando tenemos más de una tabla es usual renombrar las tablas con la declaración AS, para distinguir las variables que provienen de cada tabla y evitar problemas cuando haya variables con el mismo nombre.
- Con la expresión ON especificamos la variable de cada tabla con la que se hará el emparejamiento.
%%sql
SELECT
F.Id AS farm_id, F.B_no_membrs as farm_members,
C.Id, C.D_curr_crop
FROM Farms AS F JOIN Crops AS C ON F.Id = C.Id
WHERE F.B_no_membrs > 12 AND C.D_curr_crop = 'maize'
- Se pueden hacer joins con más de 2 tablas. En esta por ejemplo, estamos consultando cuáles son las parcelas que pertenecen a las granjas con más de 12 miembros, cultivan maíz y tienen una extensión mayor a 5 hectáreas.
%%sql
SELECT
F.Id AS farm_id, F.B_no_membrs AS farm_members,
C.Id AS Crops_Id, C.plot_Id AS crops_plot_id, C.D_curr_crop,
P.Id , P.plot_id AS plot_id, P.D02_total_plot
FROM Farms AS F
JOIN Crops AS C
JOIN Plots AS P
ON F.Id = C.Id AND F.Id = P.Id AND C.Id = P.Id
WHERE F.B_no_membrs > 12 AND C.D_curr_crop = 'maize' AND P.D02_total_plot > 5
Revisa otras entradas de este blog:
- Integración de PyQGIS con Jupyter Lab usando Anaconda
- Introducción a PyQGIS (Python + QGIS)
- Mapas de puntos con Python
- Recuadros para mapas en Geopandas
- Etiquetado de variables y valores en las encuestas de INEGI usando Python
- Generando archivos de Excel con formatos y gráficas usando Python
- Trabajando con archivos de Excel complejos en Pandas