Generando archivos de Excel con formatos y gráficas usando Python
Cómo exportar datos a archivos de Excel configurando el estilo de las celdas usando Pandas
- Aplicar formato a las celdas
- Formato condicional
- Gráficas en Excel
- Revisa otras entradas de este blog:
Elaborado por Juan Javier Santos Ochoa (@jjsantoso)
Excel es un tipo de archivo muy común para compartir datos. No a todos les encanta, pero tiene la ventaja de que es muy popular y muchas personas no familiarizadas con la programación lo usan para su análisis. Una de las funciones de Excel que no es fácil de replicar con otras herramientas es la posibilidad de aplicar estilo a las celdas y generar tablas o reportes más actractivos para presentar los datos. En esta entrada veremos cómo, usando Python, podemos exportar datos a archivos de Excel aplicando estilos y formatos a las celdas.
Como ejemplo usaremos los datos de indicadores de desarrollo del Banco Mundial. En su página puedes ver y descargar mucha información. Acá puedes decargar los archivos que en particular uso en esta entrada. Descárgalos y guárdalos en una carpeta llamada datos.
Lo que haremos es crear fichas para los metadatos que sean más fáciles de leer, ya que leer esta información tal como viene en el archivo original es un poco difícil. La idea es pasar de esto:

a esto:
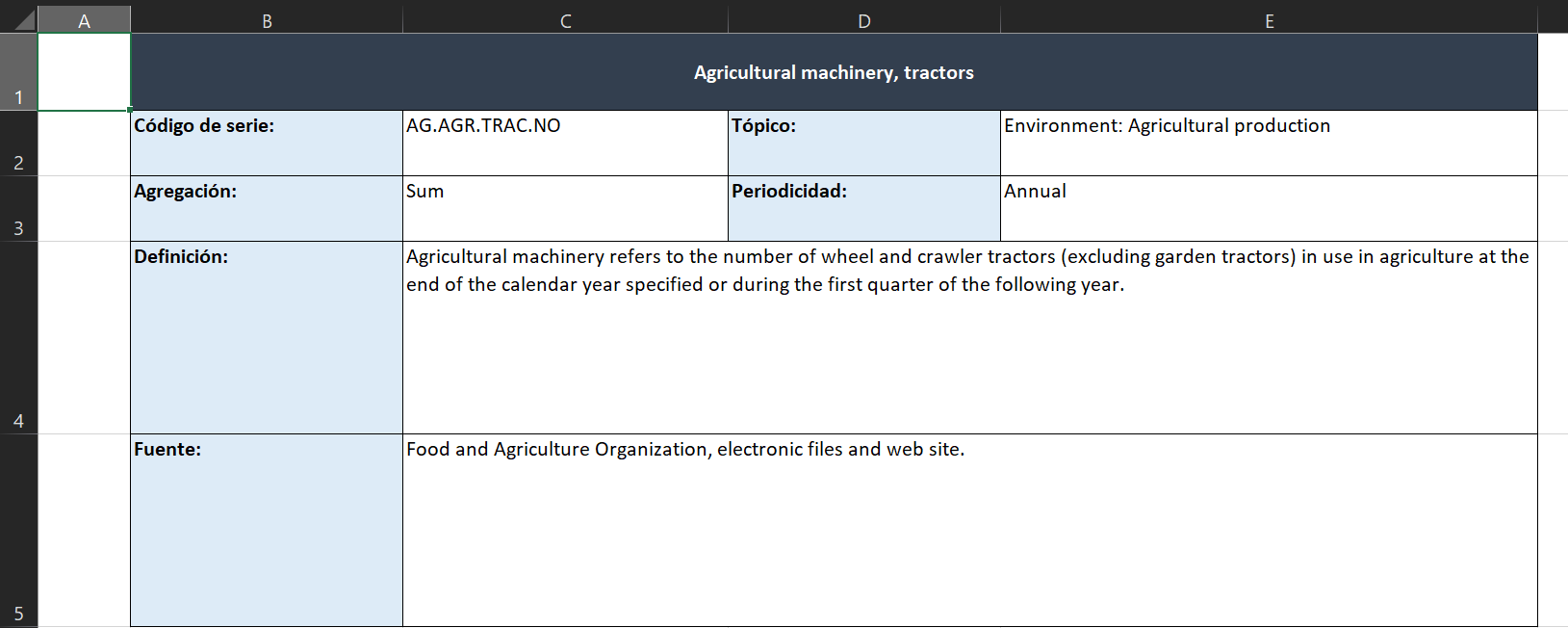
Además, usaremos el formato condicional para establecer detalles como el color de las celdas dependiendo de sus valores. Luego, como bonus, aprovechando que ya sabremos usar xlsxwriter, veremos cómo crear gráficas que se guardan dentro del archivo de Excel.
Para seguir este tutorial es necesario tener instaladas las bibliotecas pandas y xlsxwriter. La biblioteca xlsxwriter es excelente y está muy bien documentada por su autor. La mayor parte de lo que aquí hacemos se basa en sus ejemplos. xlsxwriter se instala usando pip
pip install XlsxWriterimport xlsxwriter
import pandas as pd
print(xlsxwriter.__name__, xlsxwriter.__version__)
print(pd.__name__, pd.__version__)
Por brevedad solo leeremos las 10 primeras filas del archivo que contienen los metadatos.
metadata = pd.read_csv('datos/WDISeries.csv', nrows=10).fillna('')
metadata.head()
workbook = xlsxwriter.Workbook(f'datos/fichas_metadatos.xlsx')
worksheet = workbook.add_worksheet()
Empezaremos a configurar el tamaño de las filas y columnas de la hoja. Esto lo hacemos con los métodos .set_column() y .set_row(). En .set_column() es importante especificar un rango, incluso si es una sola columna, de lo contrario obtendríamos un error. Las unidades son las mismas que usa Excel para fijar el ancho y alto de las celdas. Cuando terminamos de editar cerramos el libro con workbook.close() y esto escribe el contenido al archivo.
worksheet.set_column('B:B', 25)
worksheet.set_column('C:C', 20)
worksheet.set_column('D:D', 25)
worksheet.set_column('E:E', 50)
# Cambiamos tamaños de filas
worksheet.set_row(0, 40)
worksheet.set_row(1, 34)
worksheet.set_row(2, 34)
worksheet.set_row(3, 100)
worksheet.set_row(4, 300)
worksheet.set_row(5, 100)
workbook.close()
Así se ve el resultado hasta ahora:
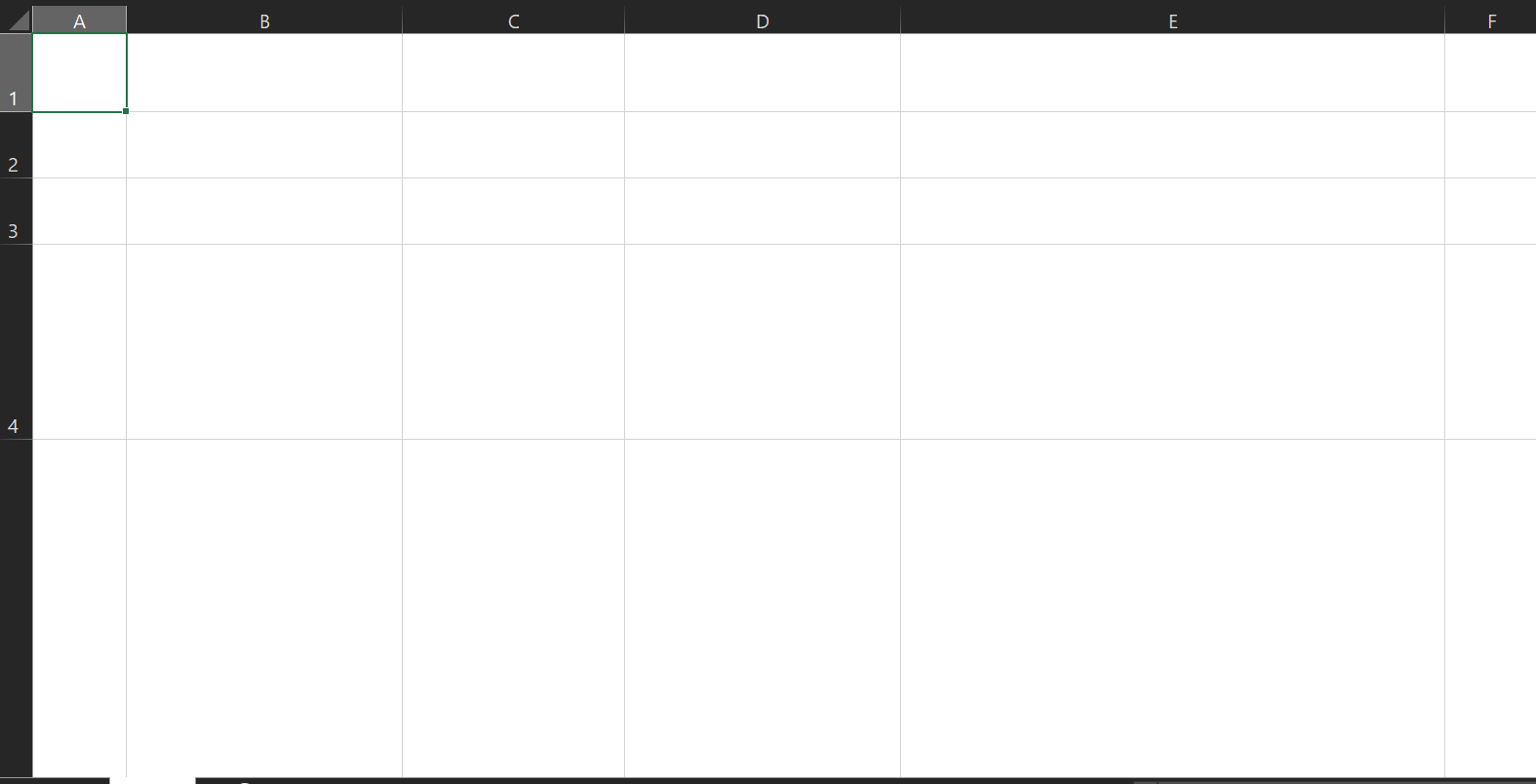 Las celdas no tienen contenido pero sí tienen tamaños diferentes.
Las celdas no tienen contenido pero sí tienen tamaños diferentes.
Ahora vamos a combinar varias celdas y escribir algo de contenido.
with xlsxwriter.Workbook(f'datos/fichas_metadatos.xlsx') as workbook:
worksheet = workbook.add_worksheet()
# Cambiamos tamaños de columnas y filas
worksheet.set_column('B:B', 25)
worksheet.set_column('C:C', 30)
worksheet.set_column('D:D', 25)
worksheet.set_column('E:E', 50)
worksheet.set_row(0, 40)
worksheet.set_row(1, 34)
worksheet.set_row(2, 34)
worksheet.set_row(3, 100)
worksheet.set_row(4, 100)
# Escribimos título
worksheet.merge_range('B1:E1', metadata.loc[0, 'Indicator Name'])
# fila 2
worksheet.write('B2', 'Código de serie:')
worksheet.write('C2', metadata.loc[0, 'Series Code'])
worksheet.write('D2', 'Tópico:')
worksheet.write('E2', metadata.loc[0, 'Topic'])
- Con el método
.merge_range()combinamos las celdas en el rangoB1:E1en una sola celda. Además, escribimos en esta misma celda el contenido del nombre del indicador (Indicator Name) del primer indicador que está en el DataFramemetadata. - Con el método
.write()escribimos contenido específico para cada una de las celdas en las siguientes filas. Por ejemplo, en la celdaB2escribimos el textoCódigo de serie:y enC2escribimos el código del indicador (Series Code) que viene en la primera fila del indicador. En las celdasD2yE2escribimos el tópico del indicador. - Aquí también cambiamos un poco la sintaxis para abrir el libro usando la expresion
with ... as ...:. De esta forma todas las operaciones deben quedar bajo la indentación y no hay necesidad de cerrar explícitamente el libro. El resultado se ve así: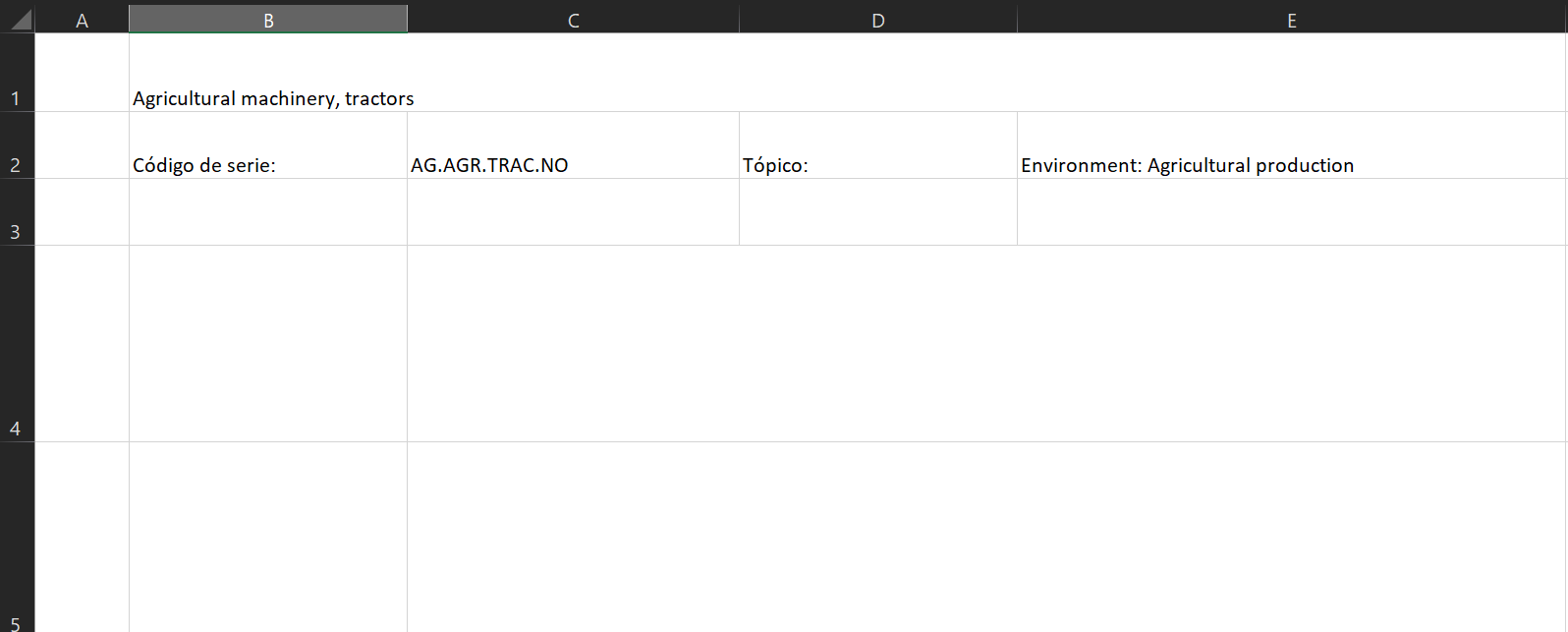
Ahora continuamos escribiendo otras variables en las filas.
with xlsxwriter.Workbook(f'datos/fichas_metadatos.xlsx') as workbook:
worksheet = workbook.add_worksheet()
# Cambiamos tamaños de columnas y filas
worksheet.set_column('B:B', 25)
worksheet.set_column('C:C', 30)
worksheet.set_column('D:D', 25)
worksheet.set_column('E:E', 50)
worksheet.set_row(0, 40)
worksheet.set_row(1, 34)
worksheet.set_row(2, 34)
worksheet.set_row(3, 100)
worksheet.set_row(4, 100)
# Escribimos título
worksheet.merge_range('B1:E1', metadata.loc[0, 'Indicator Name'])
# fila 2
worksheet.write('B2', 'Código de serie:')
worksheet.write('C2', metadata.loc[0, 'Series Code'])
worksheet.write('D2', 'Tópico:')
worksheet.write('E2', metadata.loc[0, 'Topic'])
# fila 3
worksheet.write('B3', 'Agregación:')
worksheet.write('C3', metadata.loc[0, 'Aggregation method'])
worksheet.write('D3', 'Periodicidad:')
worksheet.write('E3', metadata.loc[0, 'Periodicity'])
# fila 4
worksheet.write('B4', 'Definición:')
worksheet.merge_range('C4:E4', metadata.loc[0, 'Long definition'])
# fila 5
worksheet.write('B5', 'Fuente:')
worksheet.merge_range('C5:E5', metadata.loc[0, 'Source'])
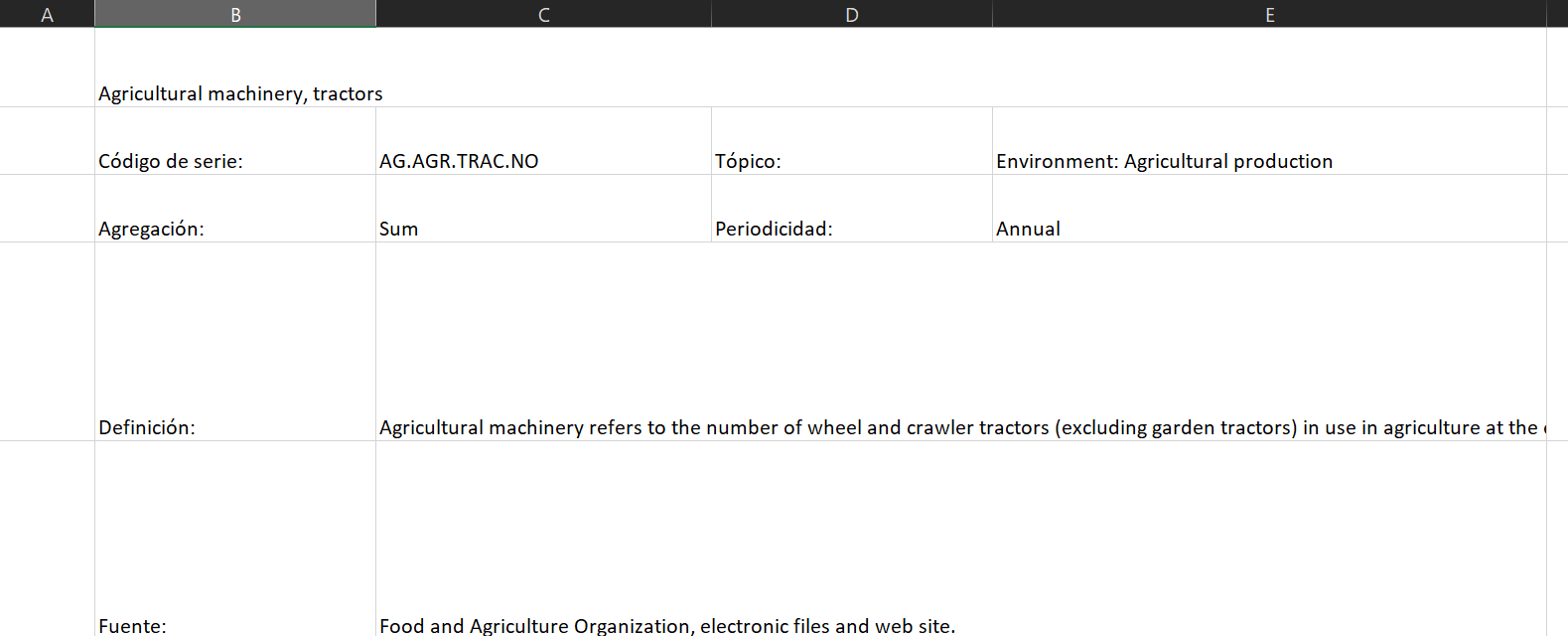
Ya que tenemos el contenido de las celdas, lo que nos falta es el aplicar formato para que se vea más atractivo.
with xlsxwriter.Workbook(f'datos/fichas_metadatos.xlsx') as workbook:
worksheet = workbook.add_worksheet()
# Cambiamos tamaños de columnas y filas
worksheet.set_column('B:B', 25)
worksheet.set_column('C:C', 30)
worksheet.set_column('D:D', 25)
worksheet.set_column('E:E', 50)
worksheet.set_row(0, 40)
worksheet.set_row(1, 34)
worksheet.set_row(2, 34)
worksheet.set_row(3, 100)
worksheet.set_row(4, 100)
# Formato de titulo
formato_titulo = workbook.add_format({
'bold': 1,
'border': 1,
'align': 'center',
'valign': 'vcenter',
'fg_color': '#333f4f',
'font_color': 'white',
'text_wrap': True})
# Formato de variables
formato_variables = workbook.add_format({
'bold': 1,
'border': 1,
'align': 'left',
'valign': 'top',
'fg_color': '#ddebf7',
'font_color': 'black',
'text_wrap': True})
# Formato del texto normal
formato_normal = workbook.add_format({
'border': 1,
'align': 'left',
'valign': 'top',
'text_wrap': True})
# Escribimos título
worksheet.merge_range('B1:E1', metadata.loc[0, 'Indicator Name'], formato_titulo)
# fila 2
worksheet.write('B2', 'Código de serie:', formato_variables)
worksheet.write('C2', metadata.loc[0, 'Series Code'], formato_normal)
worksheet.write('D2', 'Tópico:', formato_variables)
worksheet.write('E2', metadata.loc[0, 'Topic'], formato_normal)
# fila 3
worksheet.write('B3', 'Agregación:', formato_variables)
worksheet.write('C3', metadata.loc[0, 'Aggregation method'], formato_normal)
worksheet.write('D3', 'Periodicidad:', formato_variables)
worksheet.write('E3', metadata.loc[0, 'Periodicity'], formato_normal)
# fila 4
worksheet.write('B4', 'Definición:', formato_variables)
worksheet.merge_range('C4:E4', metadata.loc[0, 'Long definition'], formato_normal)
# fila 5
worksheet.write('B5', 'Fuente:', formato_variables)
worksheet.merge_range('C5:E5', metadata.loc[0, 'Source'], formato_normal)
Para ello debemos definir los formatos en el libro con el método workbook.add_format() al que le pasamos un diccionaro con las opciones de formato, como por ejemplo si queremos que el texto aparezca en negrita, que esté alineado al centro, el color del texto y el del fondo de la celda. Todas las opciones disponibles y más ejemplos se pueden encontrar en la documentación de xlsxwriter.
Aquí definimos tres tipos de formato: el formato para el nombre del indicador (formato_titulo), el formato para las celdas que tienen el nombre de la variable (formato_variables) y el formato para escribir la información (formato_normal). Para aplicar el formato a una celda, o a un conjunto de ellas, debemos pasar el objeto formato como tercer input al método worksheet.write().
Y así luce el resultado final:
Estas fichas son mucho más fáciles de leer que en el formato original.
Para finalizar esta parte solo nos queda iterar sobre todo el dataframe y crear una ficha de metadato para cada indicador, cada una en una hoja diferente:
with xlsxwriter.Workbook(f'datos/fichas_metadatos.xlsx') as workbook:
for fila in metadata.index:
# agrega nueva ahoja
worksheet = workbook.add_worksheet()
# nombre de la hoja
worksheet.name = metadata.loc[fila, 'Series Code']
# Cambiamos tamaños de columnas y filas
worksheet.set_column('B:B', 25)
worksheet.set_column('C:C', 30)
worksheet.set_column('D:D', 25)
worksheet.set_column('E:E', 50)
worksheet.set_row(0, 40)
worksheet.set_row(1, 34)
worksheet.set_row(2, 34)
worksheet.set_row(3, 100)
worksheet.set_row(4, 100)
# Formato de titulo
formato_titulo = workbook.add_format({
'bold': 1,
'border': 1,
'align': 'center',
'valign': 'vcenter',
'fg_color': '#333f4f',
'font_color': 'white',
'text_wrap': True})
# Formato de variables
formato_variables = workbook.add_format({
'bold': 1,
'border': 1,
'align': 'left',
'valign': 'top',
'fg_color': '#ddebf7',
'font_color': 'black',
'text_wrap': True})
# Formato del texto normal
formato_normal = workbook.add_format({
'border': 1,
'align': 'left',
'valign': 'top',
'text_wrap': True})
# Escribimos título
worksheet.merge_range('B1:E1', metadata.loc[fila, 'Indicator Name'], formato_titulo)
# fila 2
worksheet.write('B2', 'Código de serie:', formato_variables)
worksheet.write('C2', metadata.loc[fila, 'Series Code'], formato_normal)
worksheet.write('D2', 'Tópico:', formato_variables)
worksheet.write('E2', metadata.loc[fila, 'Topic'], formato_normal)
# fila 3
worksheet.write('B3', 'Agregación:', formato_variables)
worksheet.write('C3', metadata.loc[fila, 'Aggregation method'], formato_normal)
worksheet.write('D3', 'Periodicidad:', formato_variables)
worksheet.write('E3', metadata.loc[fila, 'Periodicity'], formato_normal)
# fila 4
worksheet.write('B4', 'Definición:', formato_variables)
worksheet.merge_range('C4:E4', metadata.loc[fila, 'Long definition'], formato_normal)
# fila 5
worksheet.write('B5', 'Fuente:', formato_variables)
worksheet.merge_range('C5:E5', metadata.loc[fila, 'Source'], formato_normal)
Formato condicional
xlsxwriter también tiene la opción de aplicar formato condicional, esto es que el formato de la celda varíe dependiendo del valor de la celda. Esto es útil cuando reportamos datos y queremos, por ejemplo, que el color de la celda esté relacionado con su valor, de forma que un valor más alto da un color más intenso. Esto se puede hacer directamente en Excel como menciona este tutorial.
Para ver cómo funciona usaremos los datos de uno de los indicadores de desarrollo que vimos antes. El indicador es el de porcentaje de la tierra que es de uso agrícola y se encuentra en el archivo indicador_tierra_agro.csv. El dataframe que creamos se llama datos.
datos = pd.read_csv('datos/indicador_tierra_agro.csv')\
.rename(columns=lambda x: str(x))
datos.head()
Vamos a seleccionar solo el nombre del país (o grupo de países) y un par de años (2010 y 2016) de datos. Estos los vamos a guardar con formato condicional usando el siguiente código:
with pd.ExcelWriter('datos/indicador_agro_formato.xlsx', engine='xlsxwriter') as excelfile:
workbook = excelfile.book
# Agregamos datos al libro
sheetname = 'agro'
datos[['Country Name', '2000', '2016']].to_excel(excelfile, sheet_name=sheetname, index=False)
# Definimos formatos
formato_porcentaje = workbook.add_format({'num_format': '0.0\%', 'font_color': '#FFFFFF'})
formato_bg_blanco = workbook.add_format({'bg_color': '#FFFFFF'})
formato_escala = {'type': '2_color_scale', 'min_color': '#D9D9D9', 'max_color': '#808080'}
worksheet = excelfile.sheets[sheetname]
# Configuramos formato a los datos
worksheet.set_column('A:A', 40, formato_bg_blanco)
worksheet.set_column('B2:C265', 20, formato_porcentaje)
worksheet.conditional_format('B2:C265', formato_escala)
Acá algunos detalles de lo que hace:
- En esta ocasión usamos la función
pd.ExcelWriterpara crear el archivoexcelfile, que a su vez tiene un libro (workbook). Usamos el método.to_excel()para guardar los datos enexcelfile. - Definimos varios formatos. El primero,
formato_porcentaje, es para que los número se vean con el símbolo de porcentaje; el segundo formato,formato_bg_blanco, es para que en la primera columna no se noten las divisiones de las celdas; y el tercero,formato_escala, es para hacer un formato de escala de 2 colores que va desde un color para el valor mínimo hasta otro en el valor máximo. Los valores intermedios reciben colores intermedios según una escala de colores lineal. - Lo que sigue es aplicar estos formatos a los valores de la hoja donde habíamos guardado los datos. El formato condicional se especifica con el método
worksheet.conditional_format().
El resultado en Excel es el siguiente:
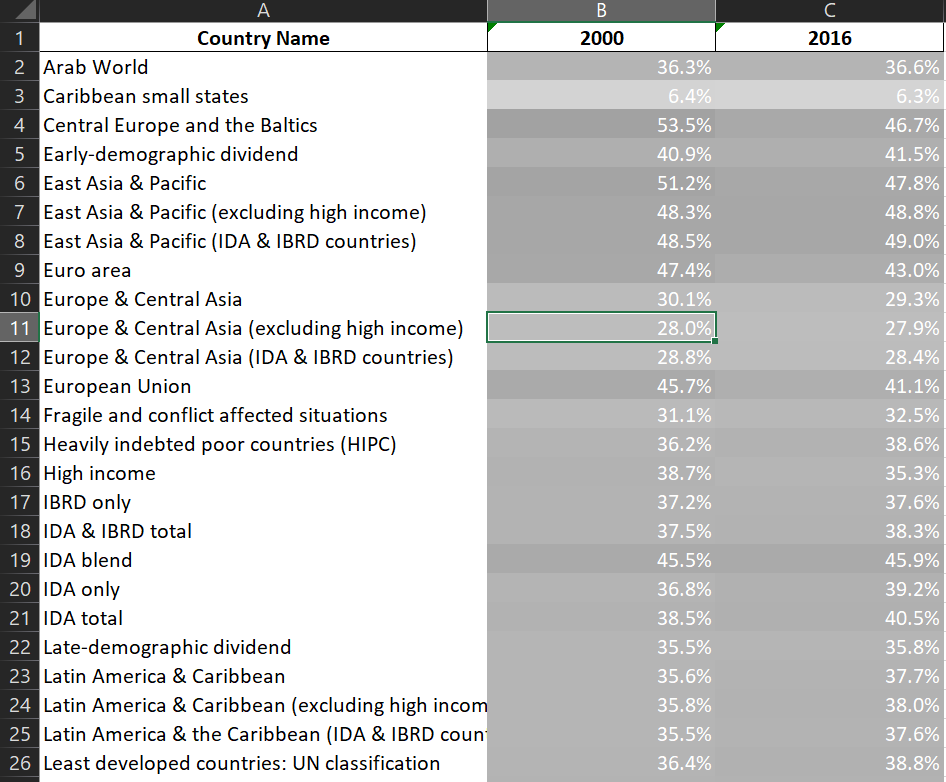
Gráficas en Excel
Por último, aprovechando que le entendemos un poco a xlsxwriter, podemos ver cómo hacer gráficas de Excel con los datos del libro. Puede parecer un poco extraño hacer gráficas de Excel usando Python si podemos hacerlas directamente en Python usando una biblioteca como Matplotlib, sin embargo, una ventaja de Excel es que cualquiera puede editar luego las gráficas, mientras que las creadas mediante Matplotlib no son directamente editables.
En este caso usamos los mismos datos anteriores del indicador de porcentaje de la tierra con uso agrícola para hacer una gráfica de barras.
with pd.ExcelWriter('datos/grafica_indicador_agro.xlsx', engine='xlsxwriter') as excelfile:
sheet_name = 'agro'
# Guarda los datos en el archivo
datos[['Country Name', '2000', '2016']].to_excel(excelfile, sheet_name=sheet_name, index=False)
# Obtiene el libro y hoja de trabajo
workbook = excelfile.book
worksheet = excelfile.sheets[sheet_name]
# Crea un objeto tipo gráfica
chart = workbook.add_chart({'type': 'bar'})
# Configura las series
chart.add_series({
'categories': f'={sheet_name}!$A$2:$A$15',
'values': f'={sheet_name}!$B$2:$B$15',
'name': f'={sheet_name}!$B$1',
'gap': 8,
})
chart.add_series({
'categories': f'={sheet_name}!$A$2:$A$15',
'values': f'={sheet_name}!$C$2:$C$15',
'name': f'={sheet_name}!$C$1',
'gap': 8,
})
# configura opciones del gráfico
chart.set_size({'width': 650, 'height': 400})
chart.set_title({'name': 'Porcentaje de tierra de uso agrícola', 'name_font': {'size': 12}})
chart.set_x_axis({'name': 'Porcentaje', 'major_gridlines': {'visible': True}})
# Introduce el grafico en la hoja
worksheet.insert_chart('D2', chart)
- Para agregar una gráfica creamos un objeto chart usando el método
workbook.add_chart(), en este caso especificando que es de tipo barra. - Al objeto chart le pasamos 2 series, la del año 2010 y la del 2016. Solo seleccionamos las primeras 15 observaciones para no sobrecargar la gráfica. Las categorías son los nombres de los países, columna
A, y las especificamos con la sintaxis de Excel para rangos de valores. Hacemos igual con los valores, que están en las columnasByC. Ponemos los nombres de las series y también la opcióngap, esta última para controlar el ancho de las barras. - Configuramos el tamaño de la gráfica, el título y la etiqueta en el eje x.
- Finalmente introducimos la gráfica en la hoja de los datos, en la celda
D2.
El resultado luce así en Excel:
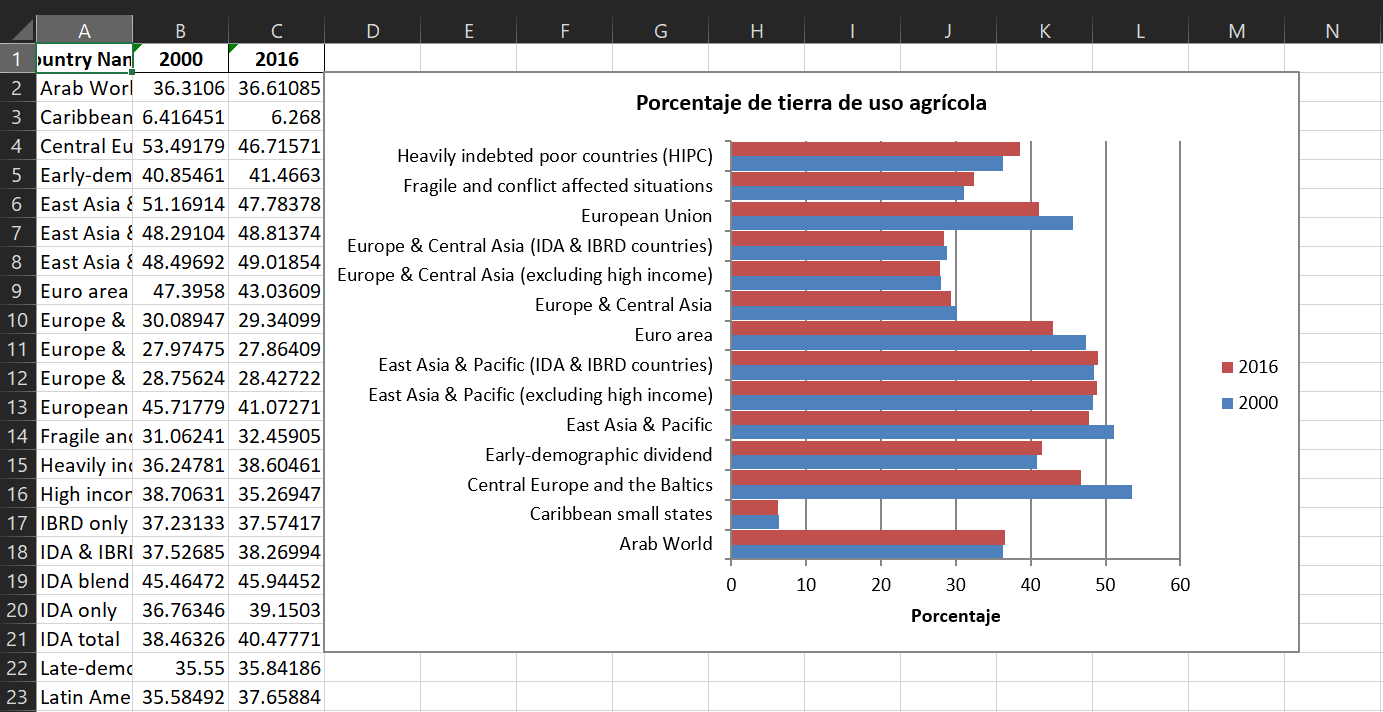
Pueden encontrar más ejemplos de gráficas en la documentación de xlsxwriter.
Con esto terminamos esta entrada cuyo objetivo principal fue introducir las funcionalidades que ofrece xlsxwriter para crear archivos de Excel con formatos mucho más ricos. A mí me ha servido mucho en mi trabajo, espero que a ti también pueda resultarte útil.
Revisa otras entradas de este blog:
- Integración de PyQGIS con Jupyter Lab usando Anaconda
- Introducción a PyQGIS (Python + QGIS)
- Mapas de puntos con Python
- Introducción a bases de datos relacionales y SQL para científicos sociales
- Recuadros para mapas en Geopandas
- Etiquetado de variables y valores en las encuestas de INEGI usando Python
- Trabajando con archivos de Excel complejos en Pandas